4. Аналитические дашборды¶
Аналитические дашборды - это набор диаграмм, отображающих состояние данных в различных представлениях и разрезах. Они предназначены для упрощения работы по их оценке, обработке, прогнозированию дальнейшего состояния и принятию решений.
4.1. Введение¶
Для интеграции аналитических дашбордов в Synergy используется комбинация инструментов Elasticsearch и Kibana.
Elasticsearch (ES) - это мощный инструмент для полнотекстового поиска и анализа данных. Он позволяет быстро загружать, выполнять поиск и анализировать большие объемы данных. Однако ES не имеет специальной визуальной оболочки, и его использование возможно с помощью набора специальных API.
Kibana - это платформа для анализа и визуализации данных. Kibana обрабатывает данные, загруженные в ES, и работает только параллельно с ним. Если работа с ES предполагает использование специального синтаксиса команд, то Kibana позволяет обрабатывать те же данные с помощью визуального интерфейса. При этом Kibana содержит интерпретатор, позволяющий использование всех возможностей и специальных команд ES.
Индексация и обработка исходных данных Synergy производится с помощью ES, дальнейший анализ и визуализация - с помощью Kibana.
В настоящем документе будут рассмотрены только некоторые из возможностей этих инструментов, непосредственно относящиеся к задаче визуализации данных. Для подробного изучения всех их возможностей и способов использования рекомендуем обращаться к официальной документации:
4.2. Индексация данных форм в ARTA Synergy¶
Запись данных в индекс производится после сохранения данных по форме. Первичная загрузка данных в ES осуществляется с помощью процесса индексации данных форм (Административное приложение -> Обслуживание системы -> Управление индексом форм). В это время для каждой формы и каждого компонента этой формы в Synergy создается несколько индексов. Каждый из этих индексов будет отображен в Kibana со своим кодом, как используемое поле.
4.2.1. Названия индексов и alias-ы¶
- Для всех данных по форме, принадлежащих реестру с идентификатором
someRegistryID, создаётся индекс с именем<index-prefix>-r-someRegistryID. - Для всех данных по форме с идентификатором
someFormIDсоздаётся индекс с именем<index-prefix>-f-someFormID. - Если итоговая длина названия индекса (как для форм, так и для реестров) превысит 255 байт, оно будет обрезано до 255 байт.
Таким образом, для каждого реестра и для каждой формы, по которым есть данные, будет создано по индексу. Если по форме создан реестр, а также созданы какие-то данные вне реестра, то в этом случае будет создано два индекса:
<index-prefix>-r-IdOfRegistryWithOtherForm<index-prefix>-f-otherID.
Примечание
Здесь описано, как получить названия всех имеющихся индексов в Elasticsearch.
Кроме этого, для удобства использования и возможности переноса конфигурации для каждого из вышеперечисленных индексов создаётся alias. Имена alias-ов формируются так:
- Для данных реестров:
r-нормализованный_код_реестра - Для данных форм без реестров:
f-нормализованный_код_формыгденормализованый_код_реестраинормализованный_код_формы- коды, соответственно, реестра и формы, в которых специальные символы , ., [, ], {, }, (, ), +, -, ?, ^, $, | заменяются на _.
Предупреждение
При этом возможна ситуация, когда нормализованные коды разных реестров совпадут и alias будет создан на на все соответветствующие индексы. Эта маловероятное затруднение может быть решено изменением кодов соответствующих реестров или форм. В случае, если это невозможно, необходимые alias-ы можно создать вручную.
При изменении кода реестра или формы в Synergy имя соответствующего alias-а также изменяется.
4.2.2. Структура документа в индексе¶
Одна единица данных в индексе Elasticsearch называется Документ. Документ содержит поля определённых типов. Каждый документ в текущем индексе соответствует одной единице данных по форме (=файлу по форме, записи реестра) и содержит следующие поля:
asfDataId- идентификатор данных по форме, типkeyword;formId- идентификатор формы, типkeyword;formCode- код формы, типkeyword;registryId- идентификатор реестра, типkeyword(содержит значение-1для данных по форме, не связанных с реестром);documentId- идентификатор документа Synergy, типkeyword;status- статус записи реестра, типnumber:- 0 - «Подготовка» (
NO_ROUTE) - это значение также устанавливается для данных по форме,
не связанных с реестром
- 1 - «В процессе» (
STATE_NOT_FINISHED) - 2 - «Активная» (
STATE_SUCCESSFUL) - 3 - «Неуспешная» (
STATE_UNSUCCESSFUL)
- 0 - «Подготовка» (
deleted- признак удаления записи реестра (0 - не удалено, 1 - удалено), типnumber(0 для данных по форме, не связанных с реестром);created- дата и время создания данных по форме, типdate;modified- дата и время изменения данных по форме, типdate.
Далее следуют поля, соответствующие компонентам формы:
- Для каждого компонента формы создаётся несколько полей документа в индексе.
- Название полей, соответствующих компоненту формы, формируется так:
идентфикаторкомпонентаформывнижнемрегистре_key_постфиксиидентфикаторкомпонентаформывнижнемрегистре_value_постфикс(данные для которых берутся, соответственно, из полейkeyиvalueданных по форме). - Для каждого поля
*_keyи*_valueсоздаются поля с нижеперечисленными постфиксами. - Для компонентов, находящихся внутри динамической таблицы, а также компонентов с мультивыбором («Объекты Synergy»), значения записываются в массив для всех постфиксов с учетом типов компонентов.
- Для компонентов, имеющих
keyиvalue, создается общее поле*_object(Object).
Постфиксы для полей *_key:
_exact- поле содержит значениеkey, приведенное к нижнему регистру, типkeyword;_sort- поле содержит точное значениеkey, типkeyword;_number- поле содержит значениеkey, приведенное к числу, типnumber;Примечание
Если поле
keyв документе пусто, в данное поле будет записано максимальное значение для типаlong: 9 223 372 036 854 775 807_date- поле содержит значениеkey, приведенное к дате; поле присутствует только для компонентов Synergy типа «Дата/время»; типdate;_double- поле содержит значениеkey, приведенное к числу, типdouble;Примечание
Данное поле создается только в том случае, если из значения
keyудалось выделить число (т.е. есть хотя бы один документ, использующий это поле, содержит числовое значение);_geo_point- поле содержит геокоординаты, которые удалось выделить из содержимого поля, типgeo_point;Примечание
Данное поле создается только в том случае, если из значения
keyудалось выделить координаты, т.е. значениеkeyсответствует формату «широта, долгота» - содержит пару чисел, разделенных запятой и являющихся валидными координатами, например:51.133333,71.433333(пара чисел, разделенных запятой, без пробелов)51.13333, 71.43333(пара чисел, разделенных запятой и пробелом)51.13, -71.43(пара чисел с точностью до сотых, разделенные запятой и пробелом)51.133, -71
пустой постфикс - поле содержит n-граммы значения
key, через пробел, типtext.
Постфиксы для полей *_value:
_exact- поле содержит значениеvalue, приведенное к нижнему регистру, типkeyword;_sort- поле содержит точное значениеvalue, типkeyword;_number- поле содержит значениеvalue, приведенное к числу, типnumber;Примечание
Если поле
keyв документе пусто, в данное поле будет записано максимальное значение для типаlong: 9 223 372 036 854 775 807_prefix- поле содержит возможные префиксы из значенияvalue, через пробел, типtext;_postfix- поле содержит возможные постфиксы из значенияvalue, через пробел, типtext;пустой постфикс - поле содержит n-граммы значения
value, через пробел, типtext.
Количество символов, которые будут включены в поля _exact и _sort, зависят от настроек, указанных
в конфигурационном файле /opt/synergy/jboss/standalone/configuration/arta/elasticConfiguration.xml.
Подробное описание этих настроек приведено в
Руководстве администратора.
4.2.3. Индексы изменения данных (историчные индексы)¶
Индексы изменения данных создаются только для тех форм и реестров, коды которых подпадают
под шаблоны (секции в конфигурационном файле arta/elasticConfiguration.xml, см. описание выше).
Имя индекса <index-prefix>-rh-someRegistryID и <index-prefix>-fh-someFormID, для реестров и
форм, соответственно. Alias-ы: rh-нормализованный_код_реестра и fh-нормализованный_код_формы.
Отличие индексов изменения данных от текущих индексов - на каждое изменение данных по форме создаётся новый документ в индексе. Кроме этого, для компонентов формы создаются только поля со следующими постфиксами:
Для
*_key:_exact_number_date_double
Для
*_value:_exact_number
Типы данных и условия создания полей такие же, как и в текущем индексе.
4.3. Визуализация данных в Kibana¶
4.3.1. Шаблоны индексов¶
Для использования индексов Elasticsearch в диаграммах Kibana необходимо указать эти индексы, используя шаблоны индексов (Index patterns). Они представляют собой маску имени, которой должны соответствовать индексы, входящие в этот шаблон.
Подробно о шаблонах индексов написано в официальном руководстве по Kibana.
Например, если необходимо создать шаблон для индексов myindex-1,
myindex-2, myindex-3 и myindex-abc, требуется создать
шаблон индекса myindex-*, где символ * означает подстановку
произвольного набора символов.
Примечание
Поскольку имена индексов данных форм составляются на основе кодов соответствующих компонентов форм, рекомендуется присваивать этим компонентам коды с учетом некоторого значащего префикса так, чтобы используемые данные можно было объединить в группу по маске имени.
В случае, если изменение кодов компонентов не представляется возможным, можно создать шаблон индекса с маской «*». Этот шаблон будет содержать все индексы Elasticsearch.
Другой способ объединения данных по форме в единый шаблон индекса -
создание шаблона для отдельного реестра или формы. Например, если
в диаграмме необходимо использовать данные реестра someRegistryID,
нужно создать шаблон индекса с названием r-someRegistryID.
Аналогично, для использования данных формы (в случае, если Synergy
не содержит реестра для этой формы) с кодом someFormID нужно
создать шаблон индекса f-someFormID.
Создание шаблонов индексов осуществляется в разделе Management - Index Patterns. Для создания нового шаблона нужно нажать на кнопку + Add New. Откроется окно создания нового индекса:
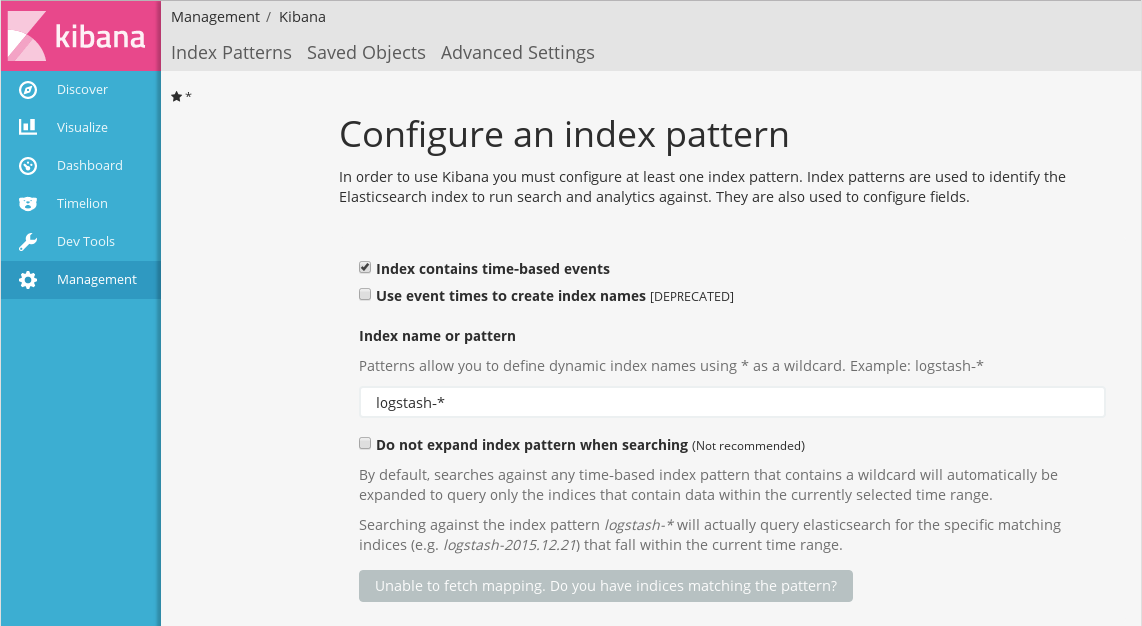
Создание нового шаблона индексов
Установленный чекбокс Index contains time-based events означает, что данные, которые входят в шаблон, содержат временные данные.
Внимание
Не рекомендуется оставлять этот чекбокс включенным, если не планируется визуализация данных во времени - например, отслеживать нагрузку на сервер в настоящий момент. Без особой настройки диаграммы, использующие такие поля, будут отображать только данные, соответствующие текущему моменту времени.
В поле Index name or pattern необходимо ввести имя шаблона индекса:
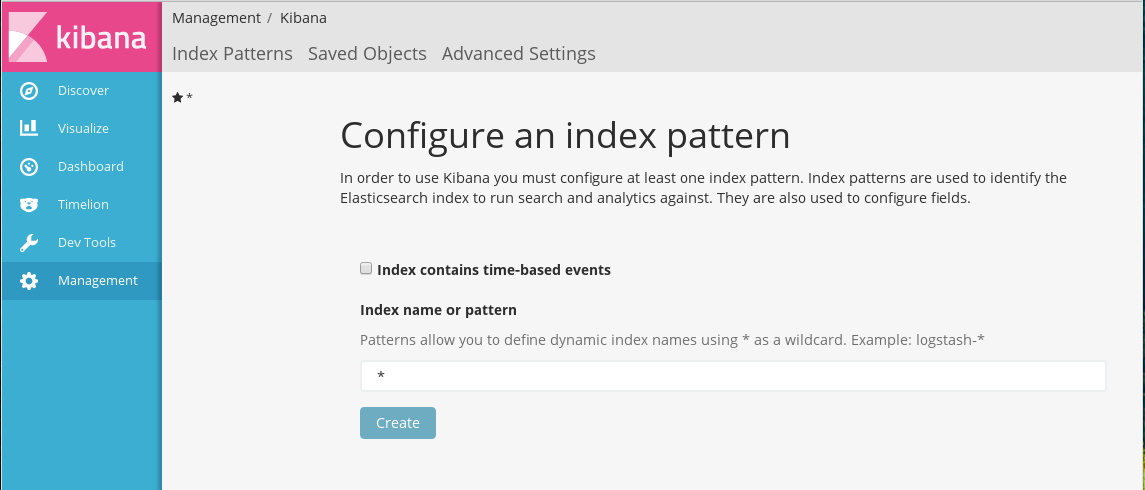
Создание нового шаблона индексов без временных данных
В случае, если Elasticsearch содержит индексы с именами, соответствующими указанному шаблону, отобразится доступная кнопка Create. Для создания шаблона индекса нужно нажать на эту кнопку.
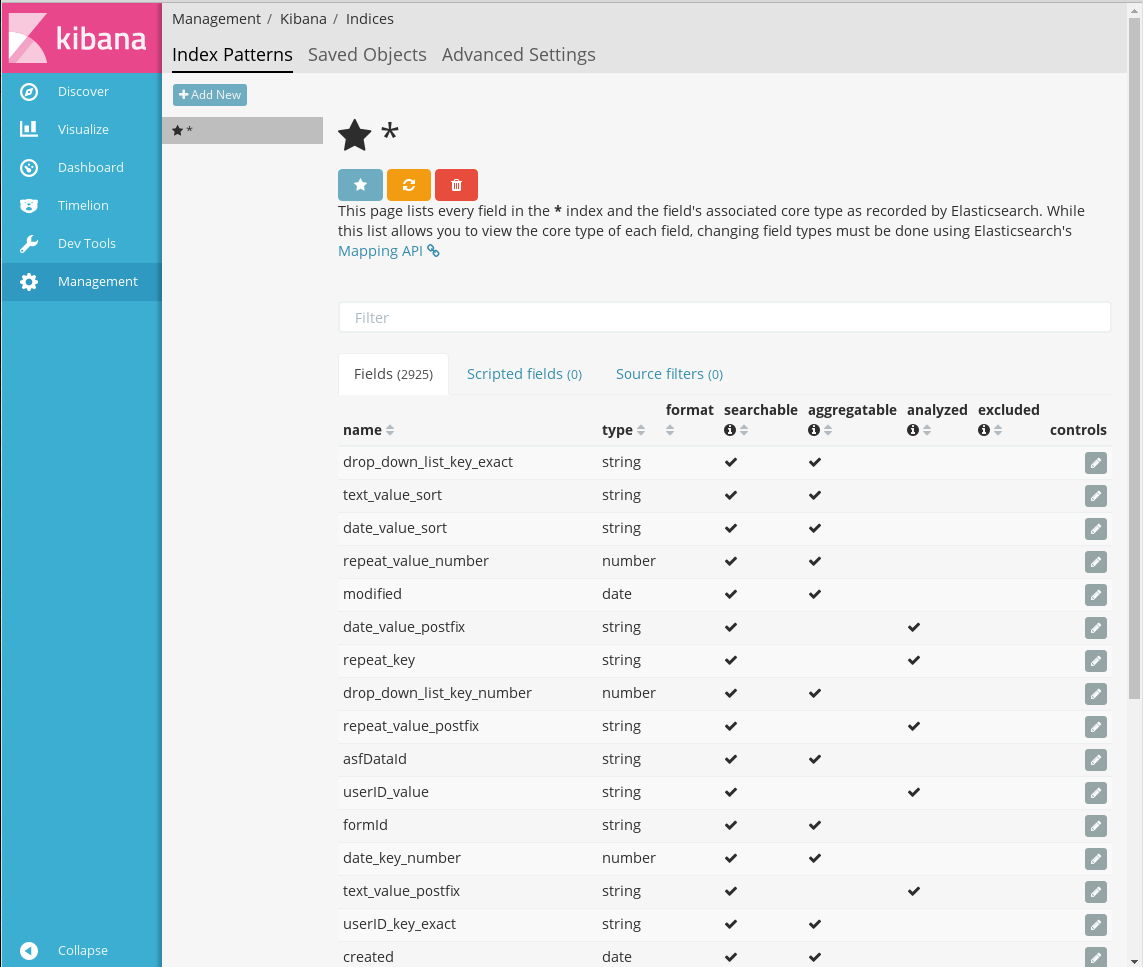
Созданный шаблон индексов
После создания шаблона отображается таблица со списком индексов, входящих в этот шаблон, и их свойствами. Эти свойства зависят от типов индексов. Типы, с которыми индексируются данные форм Synergy, описаны в разделе Индексация данных форм в ARTA Synergy.
4.3.2. Создание диаграмм¶
Kibana позволяет создавать следующие типы диаграмм:
1. Area chart - предназначена для отображения общего изменения данных во времени, когда выявление суммарного значения всех данных важнее, чем сравнение любых двух или более последовательностей. Например, полезна для отображения использования ресурсов сервера.
2. Data table - отображение данных как результата агрегации в виде таблицы.
3. Line chart - используется для отображения данных в виде линий (графиков). В отличие от Area charts, удобна для сравнения последовательностей между собой.
4. Markdown widget - вставка произвольной информации, используя синтаксис языка Markdown.
5. Metric - отображение одного числа - результата агрегации числовых данных.
6. Pie Chart - предназначена для отображения вклада нескольких частей в некоторый общий результат. Может принимать вид круговой (pie) или кольцевой (donut) диаграммы.
7. Tag cloud - отображение данных таким образом, чтобы их размер зависел от некоторого числового показателя этих данных (например, количества упоминаний).
8. Tile map - специфический тип диаграмм, использующий агрегацию
географических данных (тип поля geo_point) для их отображения на
карте.
9. Timeseries - специфический тип диаграмм, визуализирующий временные ряды.
10. Vertical bar chart - наиболее универсальная диаграмма, отображающая числовые показатели произвольных полей в виде вертикальной гистограммы.
Здесь будут рассмотрены некоторые наиболее универсальные из этих диаграмм. Для ознакомления с работой остальных типов рекомендуем обратиться к официальному руководству по Kibana.
Примечание
В диаграммах возможно использование только агрегируемых типов
полей. К ним относятся все числовые типы, а также типы date,
keyword, geo_shape и другие. Агрегируемые поля отмечены
галочкой в графе «Aggregatable» (на странице Managenent -
Index Patterns).
4.3.2.1. Общая часть¶
Все диаграммы создаются в разделе Visualize:
Kibana, раздел Visualize
В общем случае, процесс создания диаграмм состоит из трех шагов:
Выбор типа диаграммы.
Выбор источника данных шаблона индекса. В одной диаграмме возможно использование только одного шаблона, поэтому для использования в одной диаграмме данных документов по нескольким формам, необходимо использовать alias-ы.
Примечание
Этот шаг отсутствует для диаграммы Markdown widget
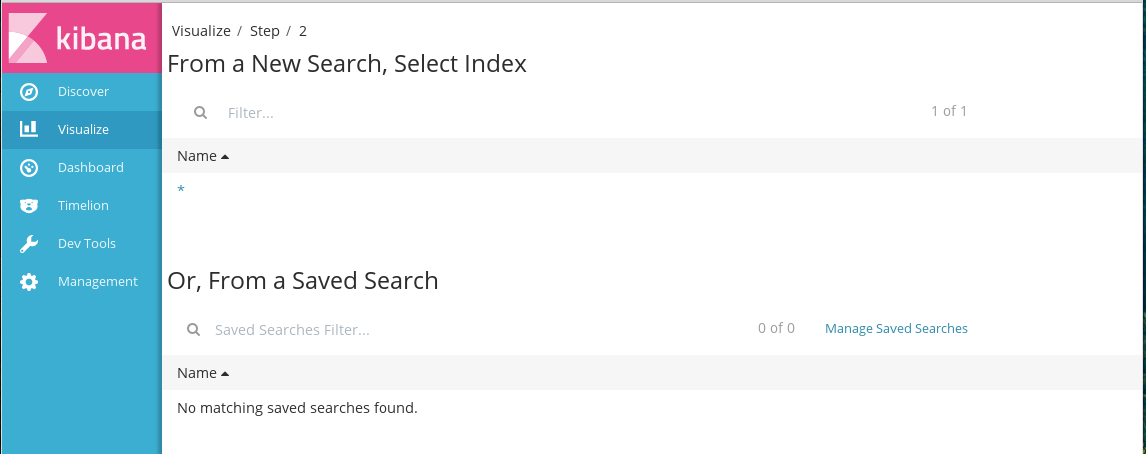
Выбор источника данных
В качестве источника данных может выступать шаблон индекса или результат поиска по данным (сохраненный или новый).
- Настройка отображаемых данных:
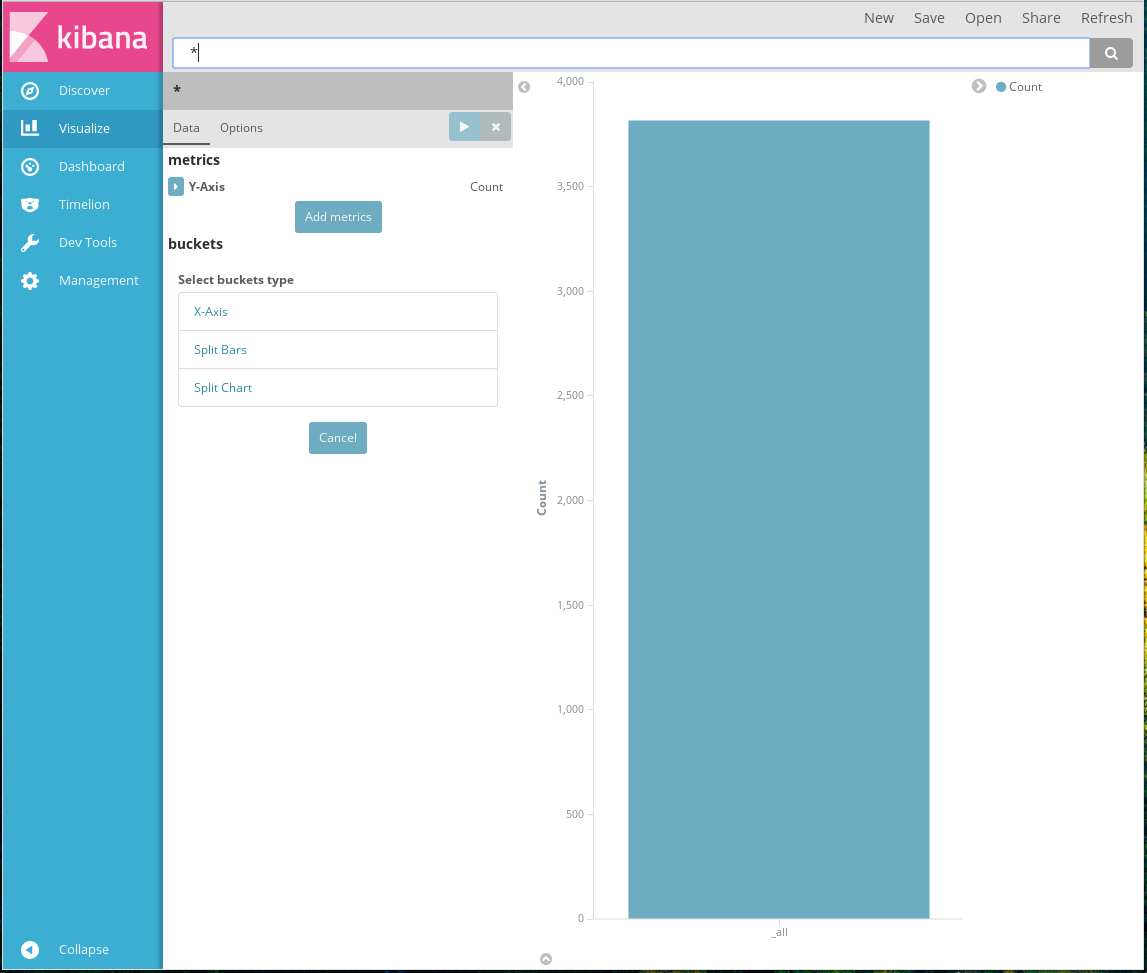
Настройка отображаемых данных
Окно настройки данных имеет стандартный вид:
В верхней части располагается панель меню с пунктами:
- New - создать новую диаграмму, переход к шагу 1;
- Save - сохранить диаграмму;
- Open - открыть существующую диаграмму;
- Share - предоставить доступ к сохраненной диаграмме;
- Refresh - обновить данные.
Ниже панели меню расположено поле поиска данных, использующее синтаксис Lucene. Данное поле используется для фильтрации данных, отображаемых в диаграмме. Например, для отображения только неудаленных документов в этой панели нужно ввести запрос:
deleted:0
где deleted - поле, генерируемое во время индексации данных
форм и хранящее значение 0, если данные в Synergy не были удалены.
Основная рабочая область окна делится на две части:
- настройка данных: выбор полей и способа их агрегации;
- просмотр результатов: отображение результата обработки выбранных данных.
В части настройки данных, в разделе Metrics, необходимо выбрать способ агрегации числовых данных, отображаемых в диаграмме. В поле Aggregation выбирается способ агрегации, а в поле Custom label вводится отображаемое название параметра.
В разделе Buckets необходимо выбрать используемые данные, числовые параметры которых будут отображены на диаграмме. Так же, как и в разделе Metrics, здесь в поле Aggregation выбирается способ агрегации, а в поле Custom label вводится отображаемое название параметра. Отличие от раздела Metrics состоит в том, что раздел Buckets позволяет группировать произвольные типы данных при выборе соответствующего типа агрегации.
Наиболее универсальным способом агрегации, используемом во всех примерах ниже, является Term. Этот способ позволяет агрегировать данные как строки, аналогично функции GROUP BY в SQL. Подробно об остальных типах агрегации можно ознакомиться в официальном руководстве по Kibana.
При выборе этого типа агрегации дополнительно отображаются поля:
- Field - выпадающий список, содержащий все поля, входящие в текущий шаблон индекса, для которых доступна агрегация.
- Order By - параметр сортировки данных - по метрике из раздела Metrics, по отдельной метрике (Custom metric) или по содержимому текущего поля (Term).
- Order - направление сортировки:
- Descending - по убыванию;
- Ascending - по возрастанию.
- Size - количество отображаемых элементов - отображаются указанное количество элементов, располагающиеся в начале списка отсортированных указанным образом данных.
- Custom label - отображаемое название параметра.
Для каждого используемого параметра, независимо от того, используется ли он в разделах Metrics или Buckets, доступна дополнительная настройка, отображаемая при нажатии на лейбл Advanced:
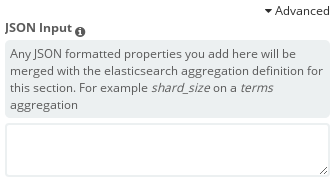
JSON Input
Она представляет собой текстовое поле, в которое можно добавить специальные свойства в формате JSON, например:
{ "script" : "doc['grade'].value * 1.2" }
В настоящем документе процесс создания диаграмм и дашбордов будет рассмотрен на примере анализа данных формы «Заявка»:
Форма «Заявка»
4.3.2.2. Pie chart¶
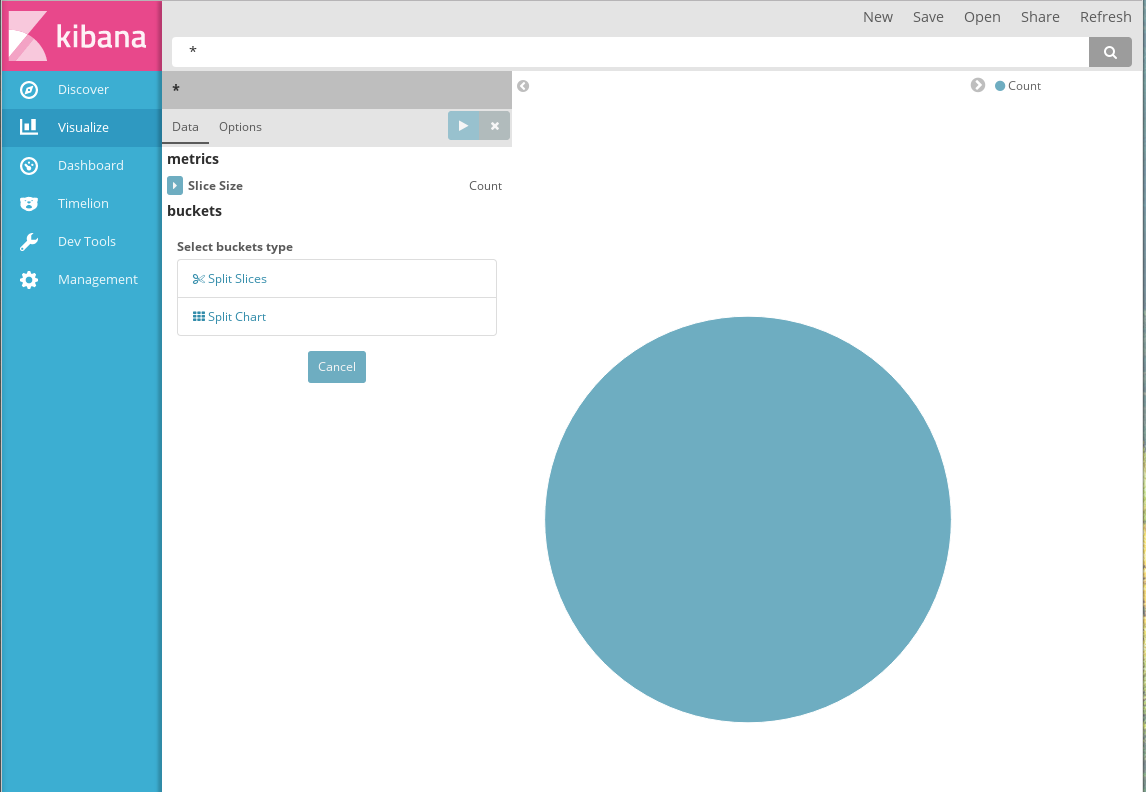
Создание диаграммы Pie chart
Для диаграммы Pie chart возможно два способа организации используемых параметров:
- Split Slices: параметр будет отображен на диаграмме как новый уровень секторов:
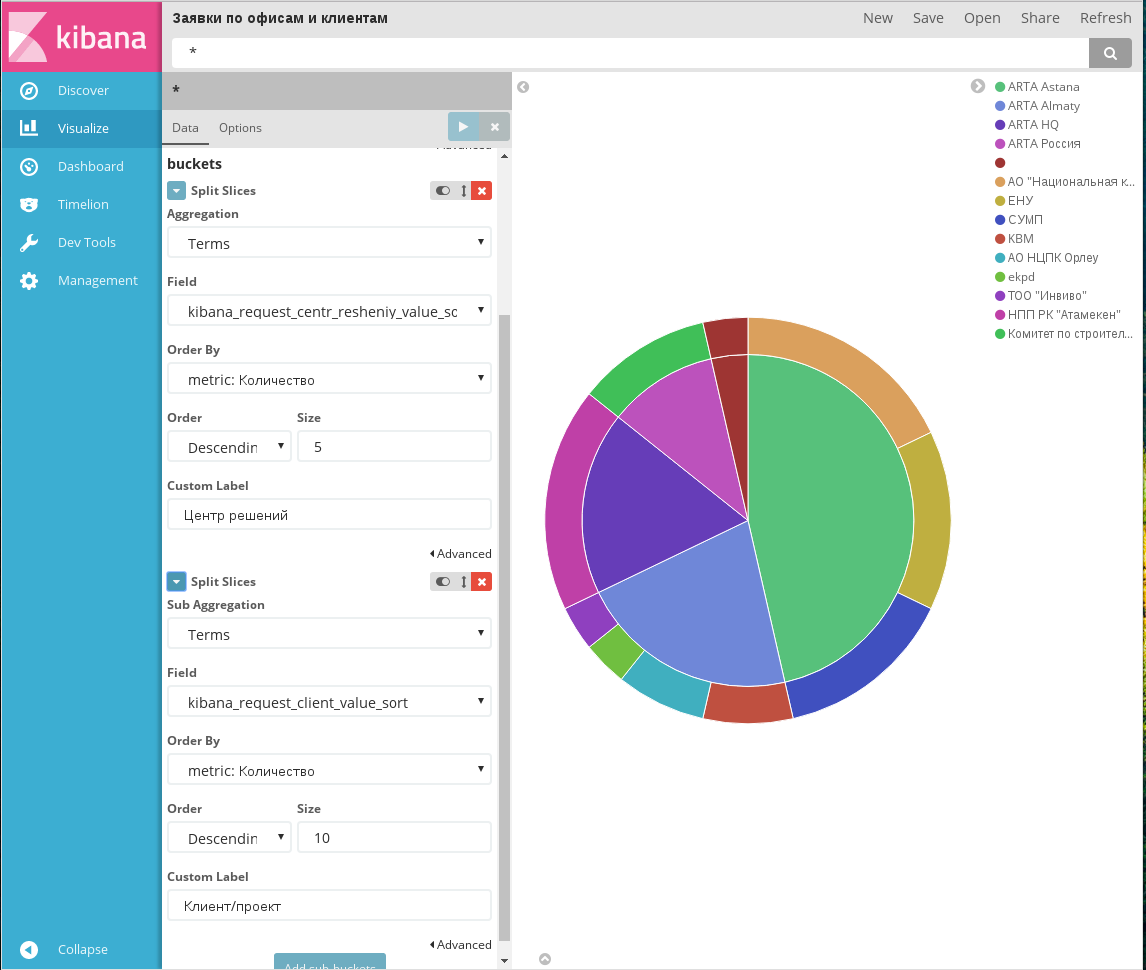
Заявки по офисам и клиентам
На этом примере в разделе Buckets в качестве первого параметра использовано поле «Центр решений» - результаты этой агрегации на диаграмме отображены во внутреннем круге.
В качестве второго параметра используется поле «Клиент/проект», и результаты этой агрегации отображаются во внешнем круге.
Примечание
Такая последовательность была выбрана в силу специфики входных данных: известно, что один центр решений занимается несколькими проектами, но одним проектом занимается ровно один центр решений.
Итоговая диаграмма позволяет оценить распределение объема заявок как по центрам решений, так и по отдельным проектам.
- Split Chart: для нового параметра будет построена
отдельная диаграмма:
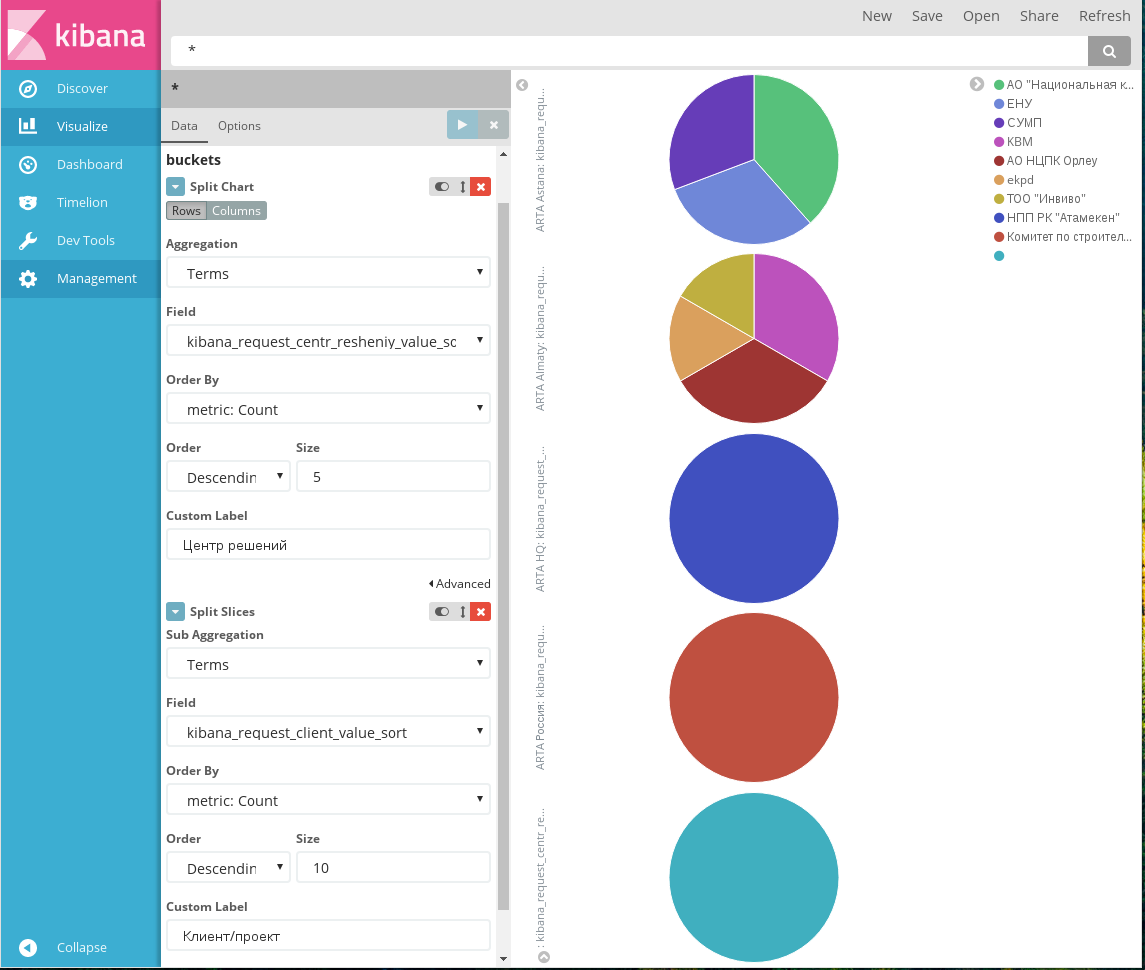
Заявки по офисам и клиентам
Здесь для каждого центра решений (поле выбрано первым параметром с типом Split Chart) отрисована отдельная диаграмма, в которой показано распределение заявок по проектам этих центров (второй параметр с типом Split Slices). Видно, что три центра решений оставляли заявки только по одному из своих проектов.
Примечание
Kibana допускает использование Split Chart только в сочетании с Split Slices, причем в этом случае параметр со Split Chart обязательно должен располагаться выше, чем параметр со Split Slices (сначала разделить данные по отдельным диаграммам, а потом разделять данные внутри каждой диаграммы).
Добавить новый параметр можно, нажав на кнопку Add sub-buckets.
Вкладка Options для этого типа диаграмм содержит три параметра:
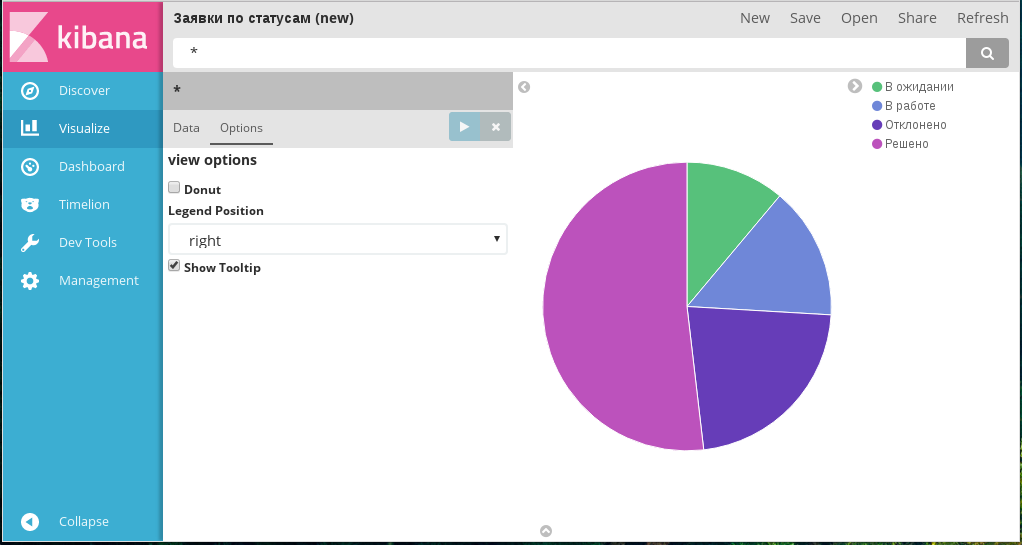
Вкладка «Опции» диаграммы Pie chart
- Вид диаграммы: если чекбокс Donut включен, диаграмма принимает вид кольцевой, если отключен - круговой (по умолчанию).
- Расположение легенды: по умолчанию справа от диаграммы.
- Показывать всплывающие подсказки при наведении на часть диаграммы: отображаются, если включен чекбокс Show Tooltip.
4.3.2.3. Data table¶
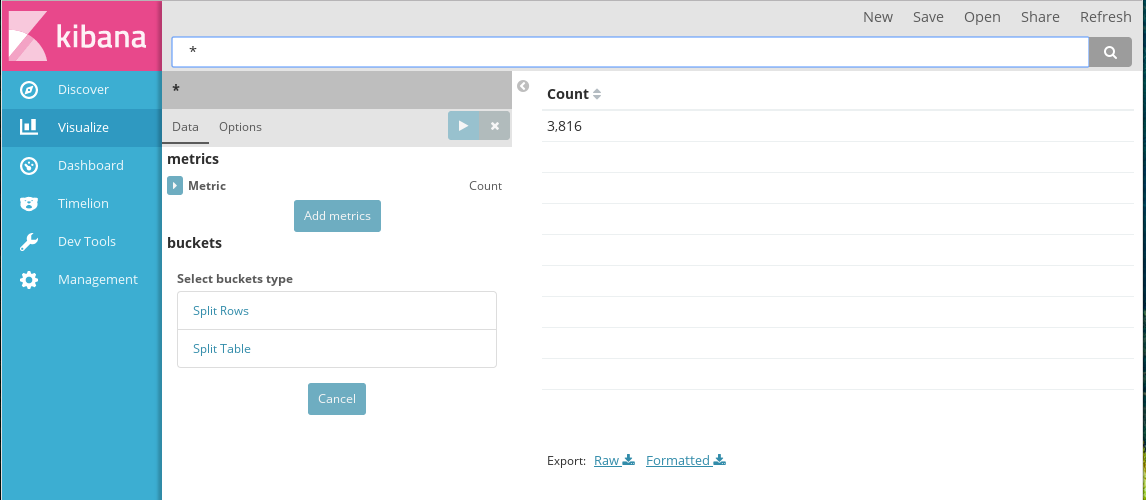
Создание диаграммы Data table
В разделе Metrics необходимо указать одну или несколько метрик, по которым будут агрегироваться данные в таблице.
В разделе Buckets необходимо указать используемые параметры и способы их агрегации. Для этого типа диаграмм также существует два способа организации входных параметров:
- Split Rows для добавления параметра как нового столбца к текущей таблице;
- Split Table для добавления параметра как отдельной таблицы.
Примечание
Функциональность этих способов полностью аналогична Split Slices и Split Chart для круговой диаграммы.
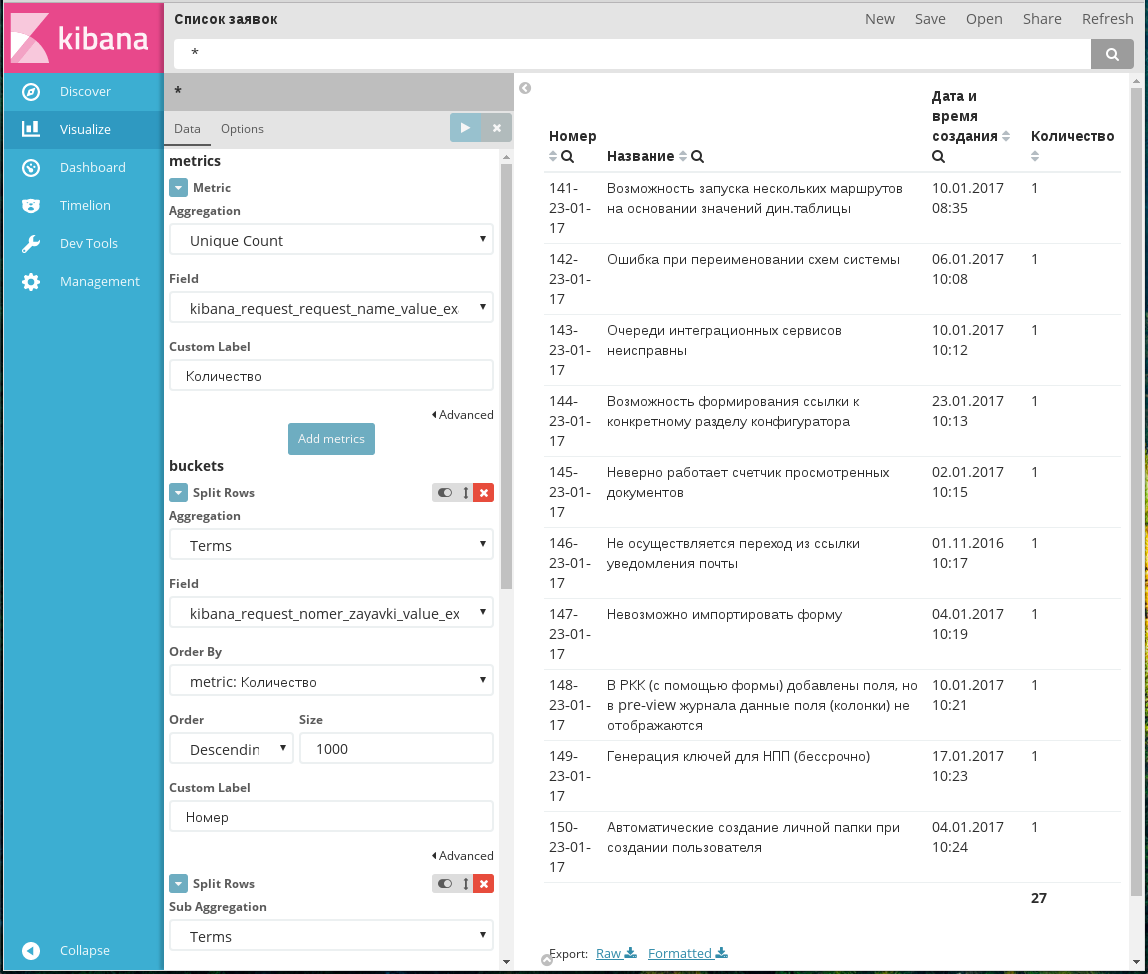
Настроены отображаемые данные в таблице
В диаграмме, указанной на рисунке выше, все параметры были добавлены как Split Rows. Для каждого параметра в разделе Buckets используется агрегация Terms.
Вкладка Options для этого типа диаграмм содержит следующие параметры:
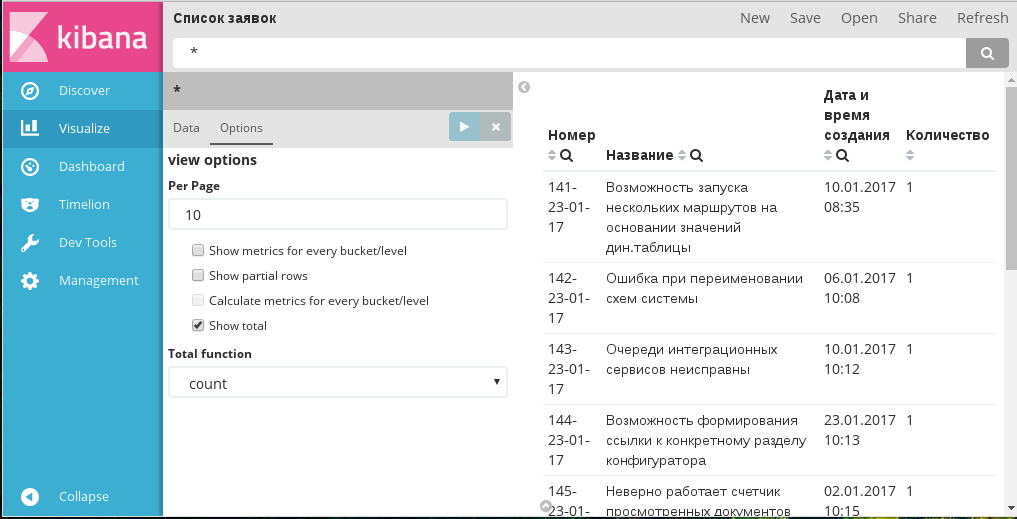
Вкладка «Опции» диаграммы Data table
- Количество отображаемых строк на странице: по умолчанию отображается 10 строк. В случае, если все записи не помещаются на одну страницу, в нижней части таблицы отображается переключатель страниц.
- Отображать метрики для каждой группы/уровня: если чекбокс включен, то для каждого столбца (в случае Split Rows) или каждой таблицы (в случае Split Table) будет добавлен столбец с результатом агрегации из раздела Metrics.
- Отображать частичные строки: если чекбокс включен, то в таблицу будут включены строки с данными, отсутствующими для выбранных индексов (полей). По умолчанию в таблице отображаются только полностью заполненные строки.
- Считать метрики для каждой группы/уровня: чекбокс, недоступный для ручной установки. Его значение зависит от параметра «Отображать метрики для каждой группы/уровня».
- Отображать итоговые значения: если чекбокс включен, то на каждой странице таблицы для каждой отображаемой метрики будет указано итоговое значение этой метрики для всех данных таблицы.
- Функция для итогов: выбор функции для подсчета итоговых значений метрик. Параметр доступен только в том случае, если установлен чекбокс «Отображать итоговые значения».
4.3.2.4. Vertical bar chart¶
Создание диаграммы Vertical bar chart
В диаграмме этого типа по оси Y располагаются метрики (параметры в Metrics), с по оси X - группы (параметры в Buckets).
Доступно указание нескольких метрик на оси Y и не больше одной группы каждого типа:
- X-Axis
- Split Bars
- Split Chart
Примечание
Функциональность Split Bars и Split Chart полностью аналогична Split Slices и Split Chart для круговой диаграммы.
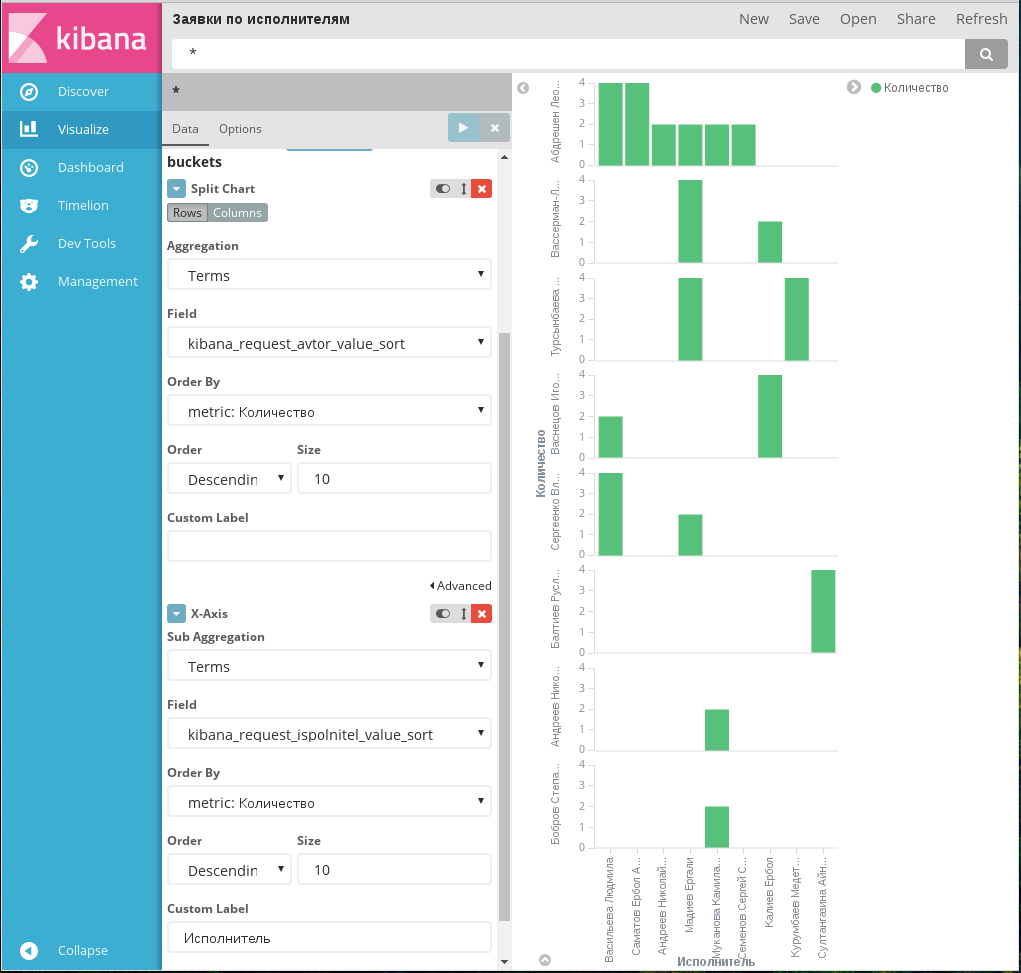
Диаграмма Vertical bar chart, пример 1
На примере 1 показан результат разделения параметров по диаграммам: отображается количество заявок, поданных разными авторами и выполненных разными исполнителями. Для этого исполнители расположены по оси Х, а для каждого автора заявок отрисована отдельная диаграмма.
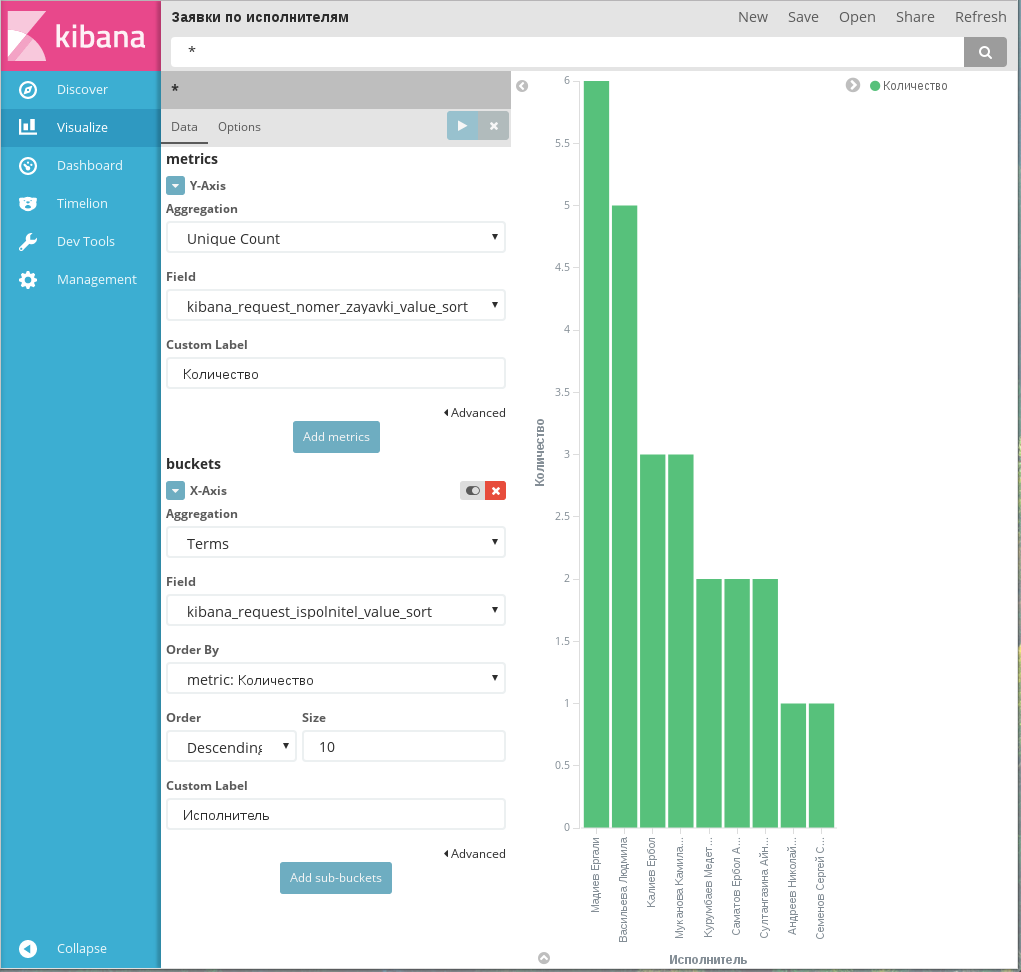
Диаграмма Vertical bar chart, пример 2
На примере 2 показана простая гистограмма, визуализирующая количество заявок, выполненных разными исполнителями.
4.3.2.5. Tile map¶
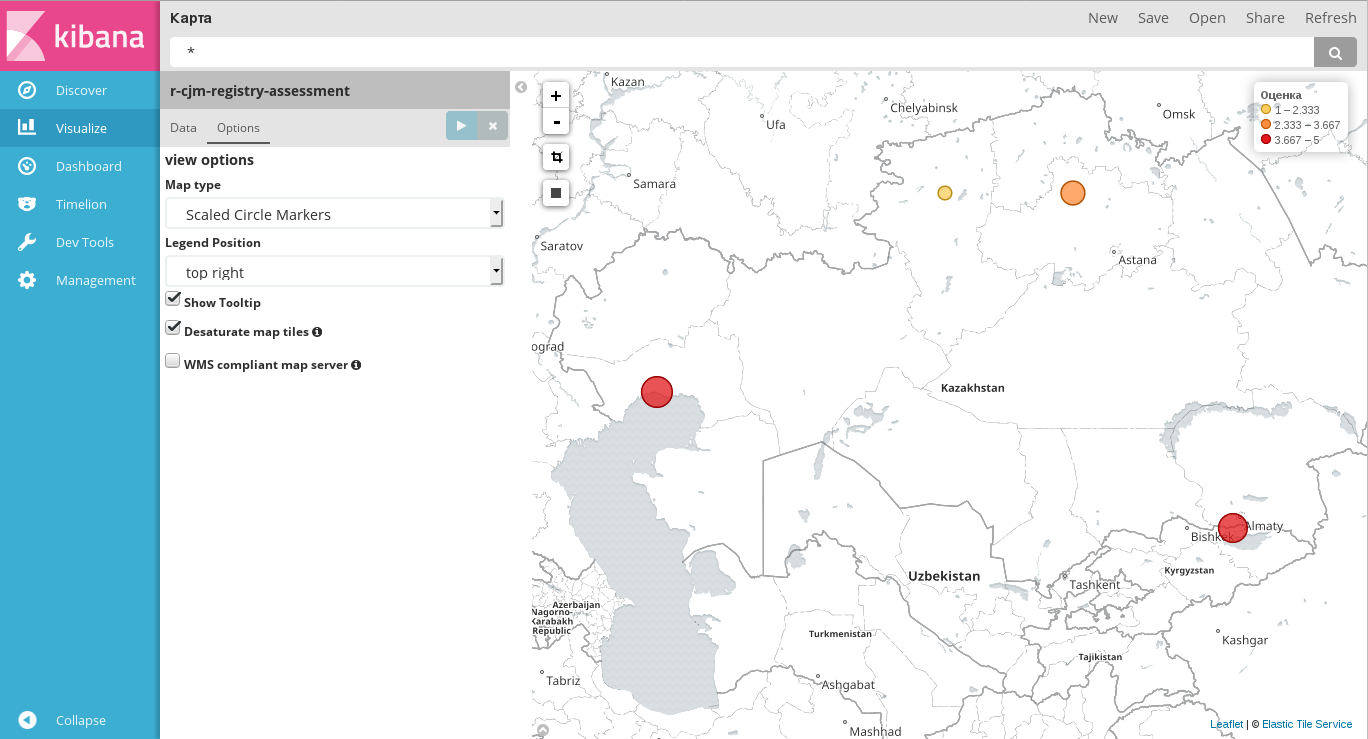
Создание диаграммы Tile map
В диаграмме этого типа визуализируются числовые метрики (параметры в Metrics), относящиеся к разным географическим точкам (параметры в Buckets).
Доступно указание ровно одной метрики и одного разделения по координатам.
В разделе Buckets может быть указан только один тип аггрегирования - Geohash,
использующийся для данных типа geo_point.
Подсказка
Для получения координат в документах индексов Elasticsearch необходимо записать
пару чисел в key компонента формы. Проще всего это сделать в компонентах
типов «Выпадающий список», «Выбор вариантов» или «Переключатель вариантов»:
для них достаточно в качестве наименования элемента указать название географической
точки, а в качестве значения - пару координат, например:
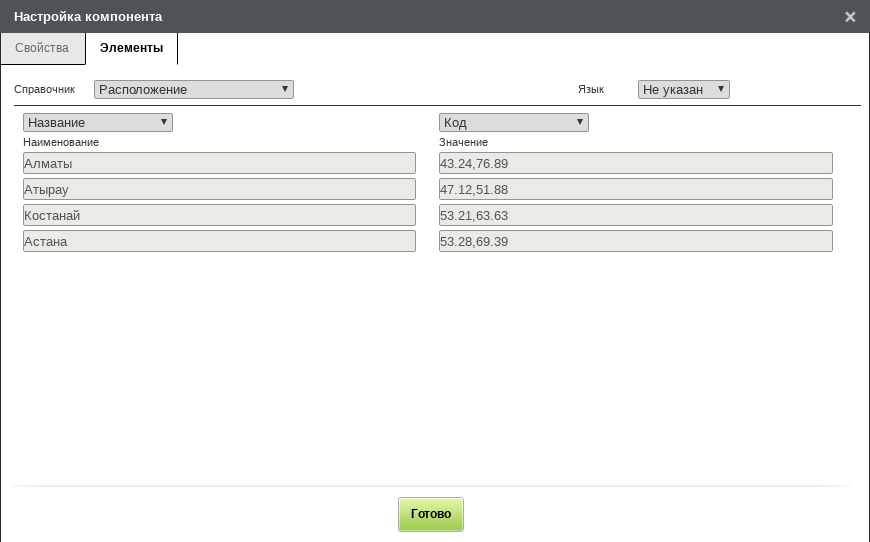
Настройка координат в компоненте на форме
4.3.2.6. Markdown widget¶
Специфичный тип диаграммы, который не имеет раздела Data. В левой части рабочей области располагается поле ввода текста с использованием синтаксиса языка Markdown, в правой части отображается результат разметки текста:
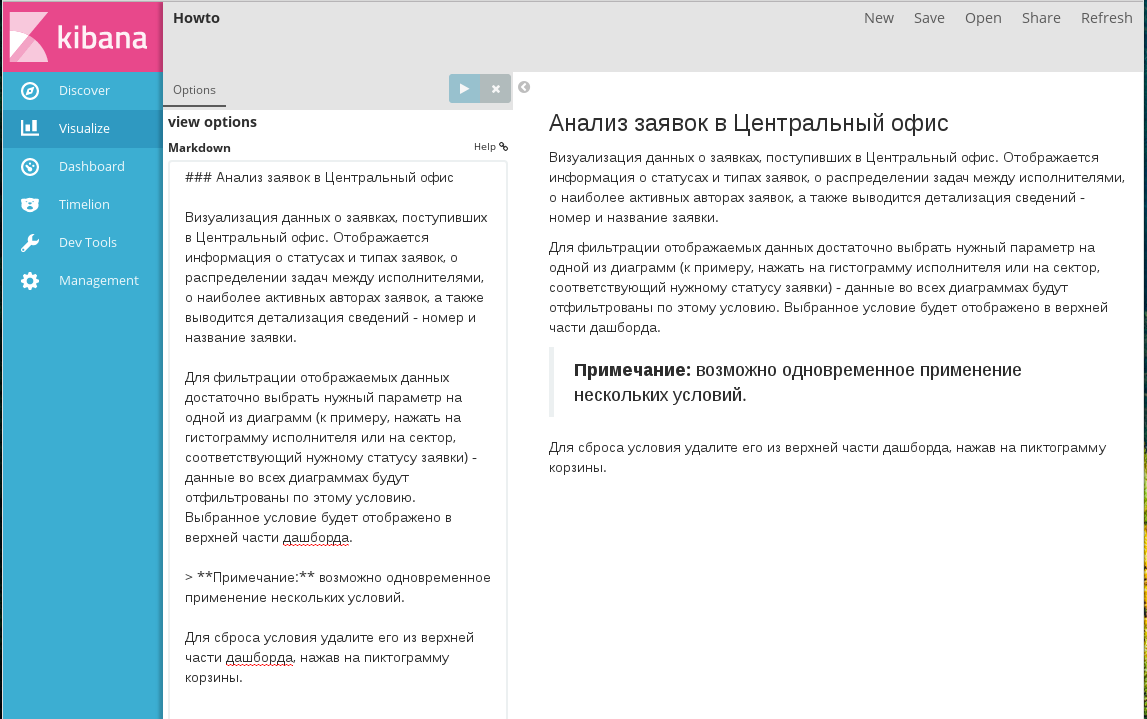
Создание Markdown widget
Эта диаграмма не имеет никаких особых настроек.
4.3.2.7. Metric¶
Диаграмма Metric работает только с числовыми данными, поэтому для нее доступны только агрегации типа Metrics:
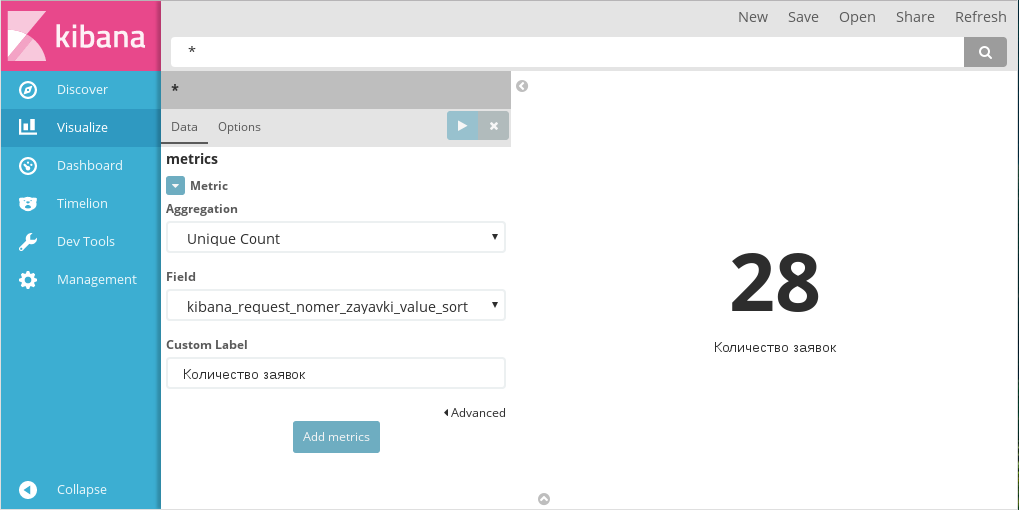
Создание Metrics
Добавить новую метрику можно, нажав на кнопку Add metrics. Новая метрика будет добавлена как новое отображаемое число.
Вкладка Options для этого типа диаграмм содержит только один параметр - размер шрифта:
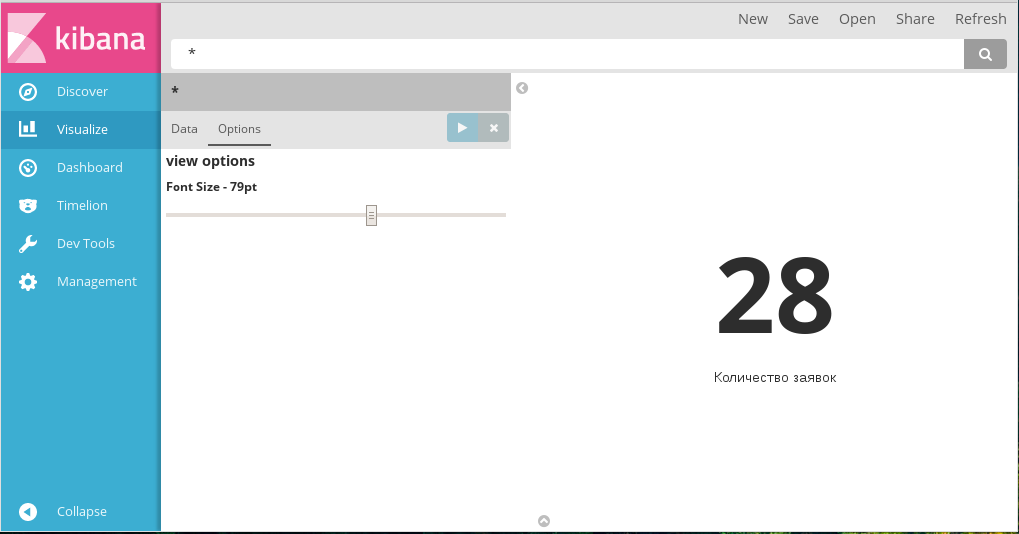
Вкладка «Опции» диаграммы Metrics
4.3.2.8. Tag cloud¶
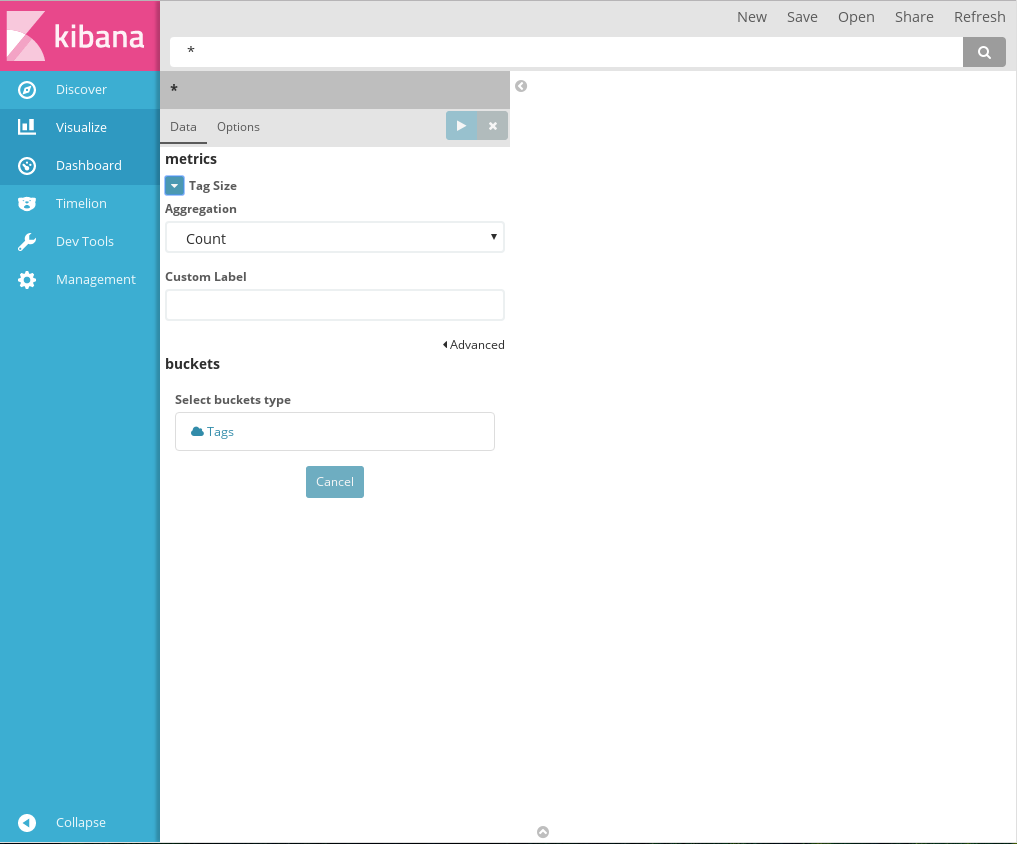
Создание Tag cloud
В диаграмме Tag cloud возможно использование только одной агрегации Metrics и только одного, специального способа организации данных в Buckets - Tags. Добавление новых метрик или новых групп недоступно.
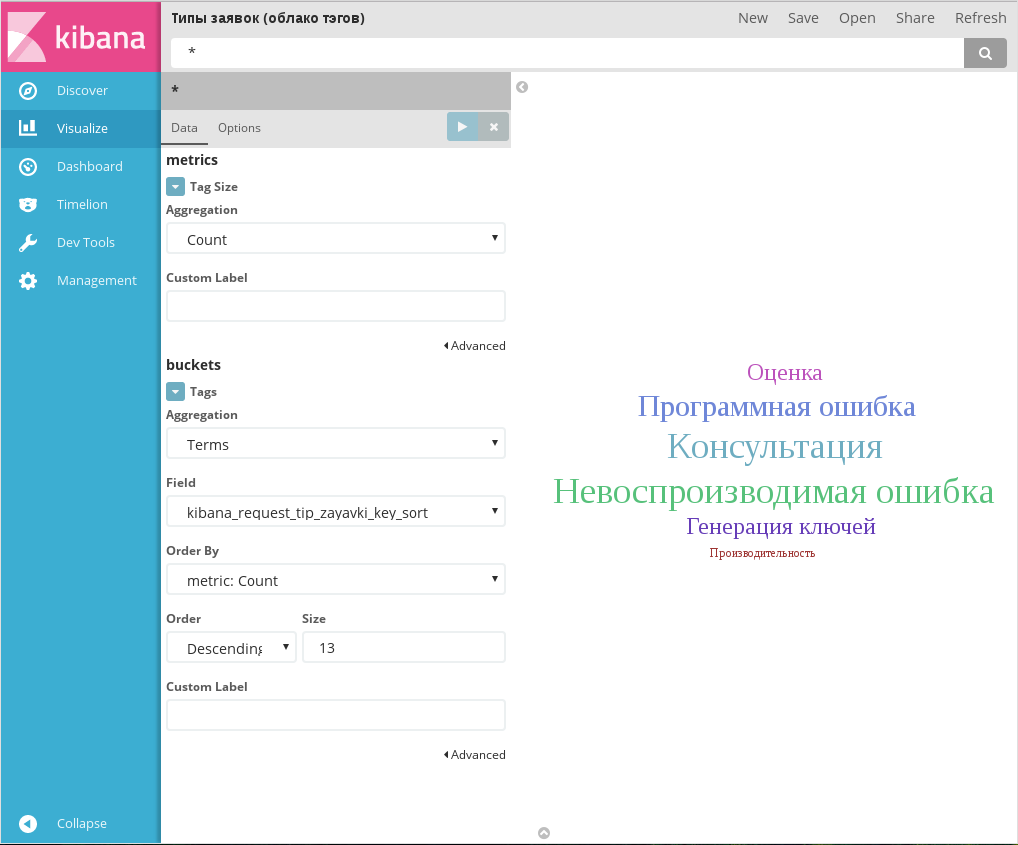
Пример диаграммы Tag cloud
Вкладка Options содержит следующие параметры:
- зависимость размера текста от числовой метрики: линейная, логарифмическая или квадратичная;
- ориентация тэгов: горизонтальная, вертикальная или произвольная;
- границы размеров шрифта в тэгах;
- отображать название используемых параметров: чекбокс, по умолчанию выключен.
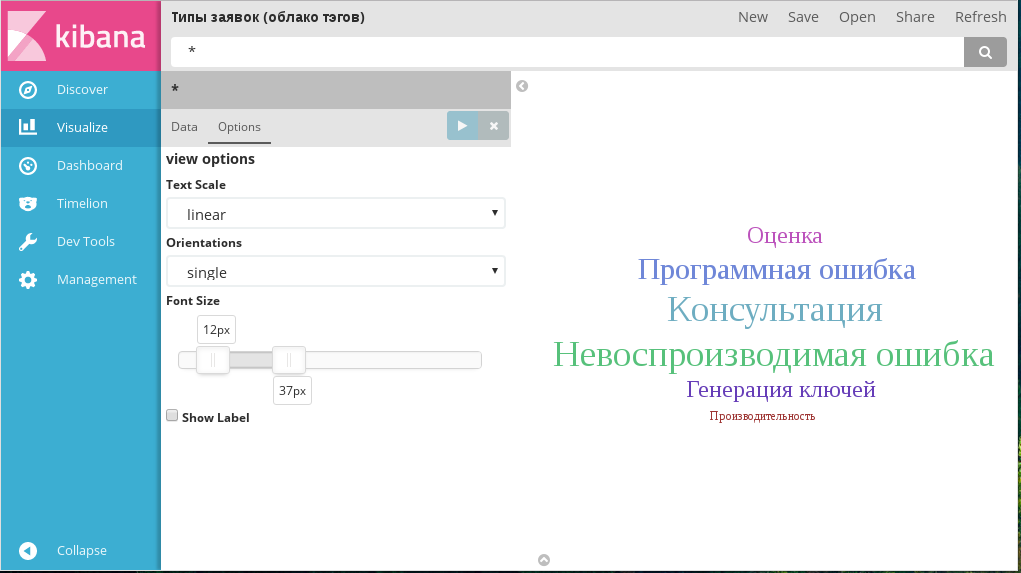
Вкладка «опции» диаграммы Tag cloud
4.3.2.9. Создание дашбордов¶
Дашборд представляет собой панель, на которой располагаются ранее созданные диаграммы, с широкими возможностями настроек отображения, обновления и публикации.
Создание дашбордов производится в разделе Dashboard:
Kibana, раздел Dashboard
Панель меню этого раздела содержит пункты:
- New - переход к строке поиска и созданию нового фильтра.
- Add - добавить новый дашборд, содержит перечень сохраненных диаграмм и результатов поиска:
Добавление диаграммы на дашборд
Каждая диаграмма в списке сопровождается пиктограммой, указывающей на тип диаграммы.
- Save - сохранить текущий дашборд.
- Open - открыть ранее сохраненный дашборд.
- Share - настройки публикации дашборда. Доступны только для сохраненного дашборда.
- Options - настройка внешнего вида дашборда, содержит единственный чекбокс «Использовать темную тему», по умолчанию выключен.
- Time range - настройка режима отображения данных для диаграмм.
В самой панели отображается настроенный период. По умолчанию отображаются
данные за последние 15 минут. Данная настройка актуальна, если есть
необходимость отображения данных в режиме реального времени. Доступна
возможность быстрой настройки периода (за сегодня, за эту неделю,
за последний год), указания абсолютной (дата и время в формате
YYYY-MM-DD HH:mm:ss.SSS) или относительной (например, последние 25 минут) настройки.
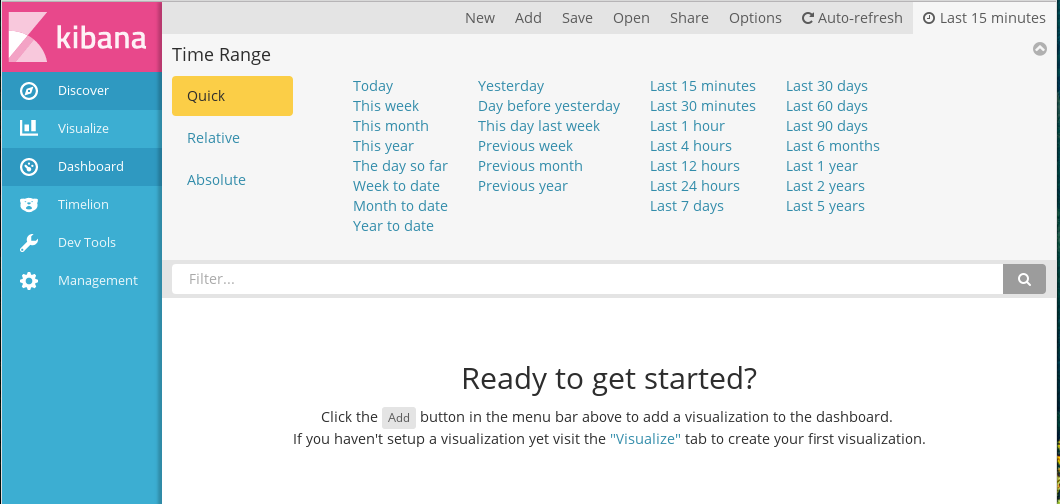
Настройки периода отображения
При переходе к этой настройке в панели меню появляется дополнительный пункт Auto-refresh. Он предназначен для настройки интервала обновления диаграмм:
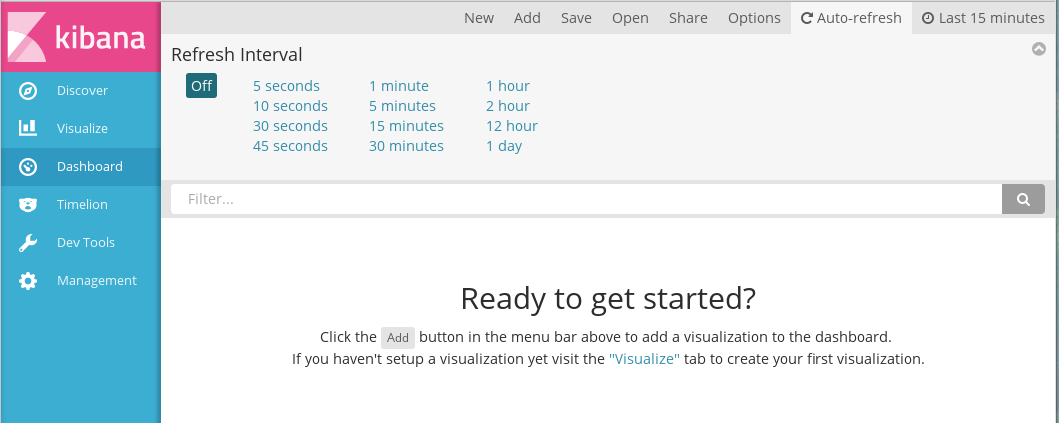
Настройки периода обновления диаграмм
Данная настройка актуальна, если данные, на основе которых построены диаграммы, регулярно обновляются: например, в терминах Synergy, если необходимо отображать актуальные данные реестров, в которых регулярно появляются новые записи.
По умолчанию автообновление выключено.
Для всех диаграмм на дашборде возможно одновременное применение условий для отображаемых данных. Для этого нужно ввести условие в панель поиска, располагающуюся ниже панели меню. Функциональность этой панели для раздела Dashboards аналогично панели в разделе Visualize.
4.3.2.10. Добавление и настройка диаграмм¶
Для добавления ранее сохраненной диаграммы на дашборд необходимо выбрать пункт меню Add. Отобразится список доступных диаграмм (илл. «Добавление диаграммы на дашборд» выше). Необходимо кликнуть на нужную диаграмму - она будет добавлена на дашборд:
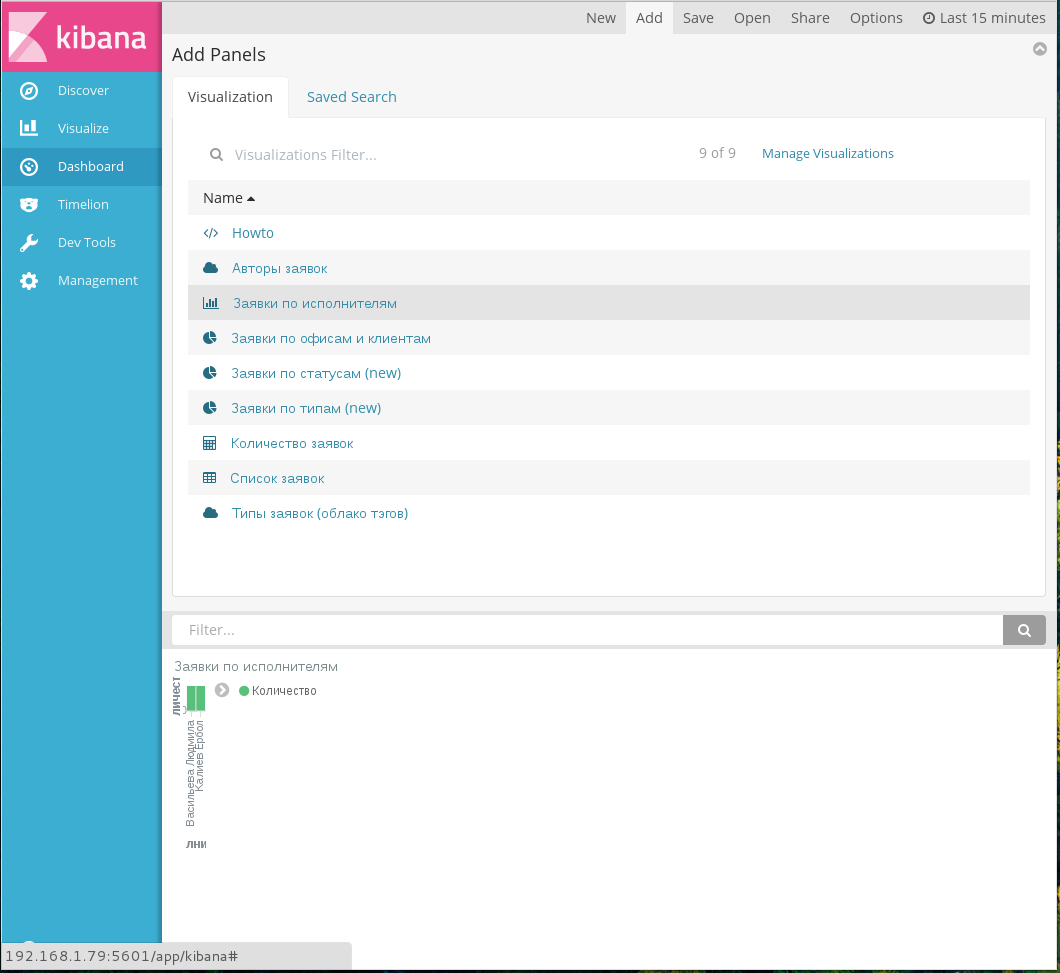
Добавлена панель диаграммы на дашборд
Размер отображаемой диаграммы можно изменить, потянув за левый нижний угол панели диаграммы:

Изменение размера панели диаграммы
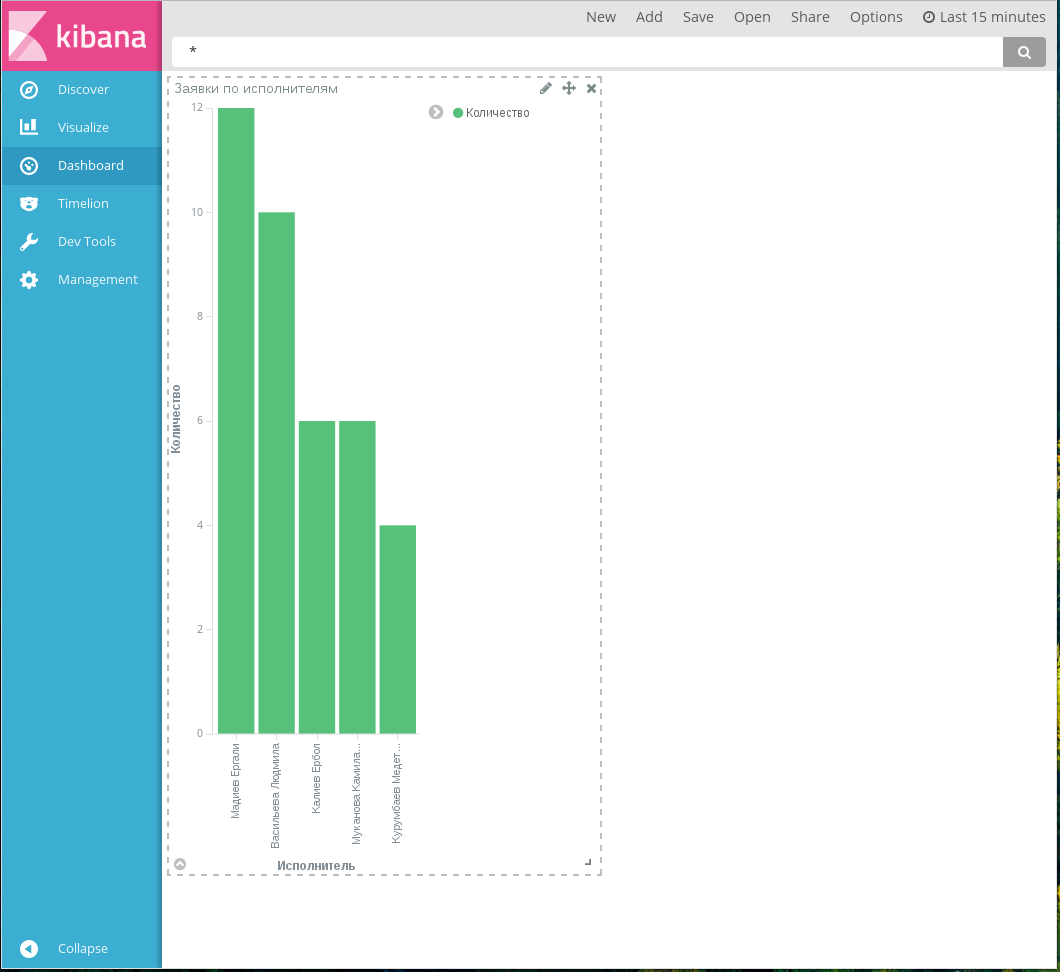
Изменен размер панели диаграммы
В случае, если все данные диаграммы не помещаются на панели, в нее будет добавлен внутренний скролл.
Примечание
Если на определенном размере панели диаграммы «Облако тэгов» не помещаются все данные, в ней будут отображены только наиболее популярные тэги (столько, сколько возможно уместить на указанном размере панели), и будет отображен текст, предупреждающий, что для отображения всех данных необходимо увеличить размер панели диаграммы:

На панели диаграммы отображаются пиктограммы управления:
 - изменить диаграмму (переход к настройкам отображаемых данных диаграммы в разделе Visualize);
- изменить диаграмму (переход к настройкам отображаемых данных диаграммы в разделе Visualize); - переместить панель диаграммы на дашборде;
- переместить панель диаграммы на дашборде; - удалить панель диаграммы с дашборда;
- удалить панель диаграммы с дашборда; - изменить размер панели диаграммы;
- изменить размер панели диаграммы; - отобразать/свернуть источники данных в виде таблицы, запроса или
исходных данных Elasticsearch, а также статистику запроса данных для этой диаграммы;
- отобразать/свернуть источники данных в виде таблицы, запроса или
исходных данных Elasticsearch, а также статистику запроса данных для этой диаграммы; - отобразить/свернуть легенду.
- отобразить/свернуть легенду.
Примечание
Количество диаграмм, располагаемых на дашборде, не ограничено, наложение диаграмм друг на друга не допускается.
Пример готового дашборда:
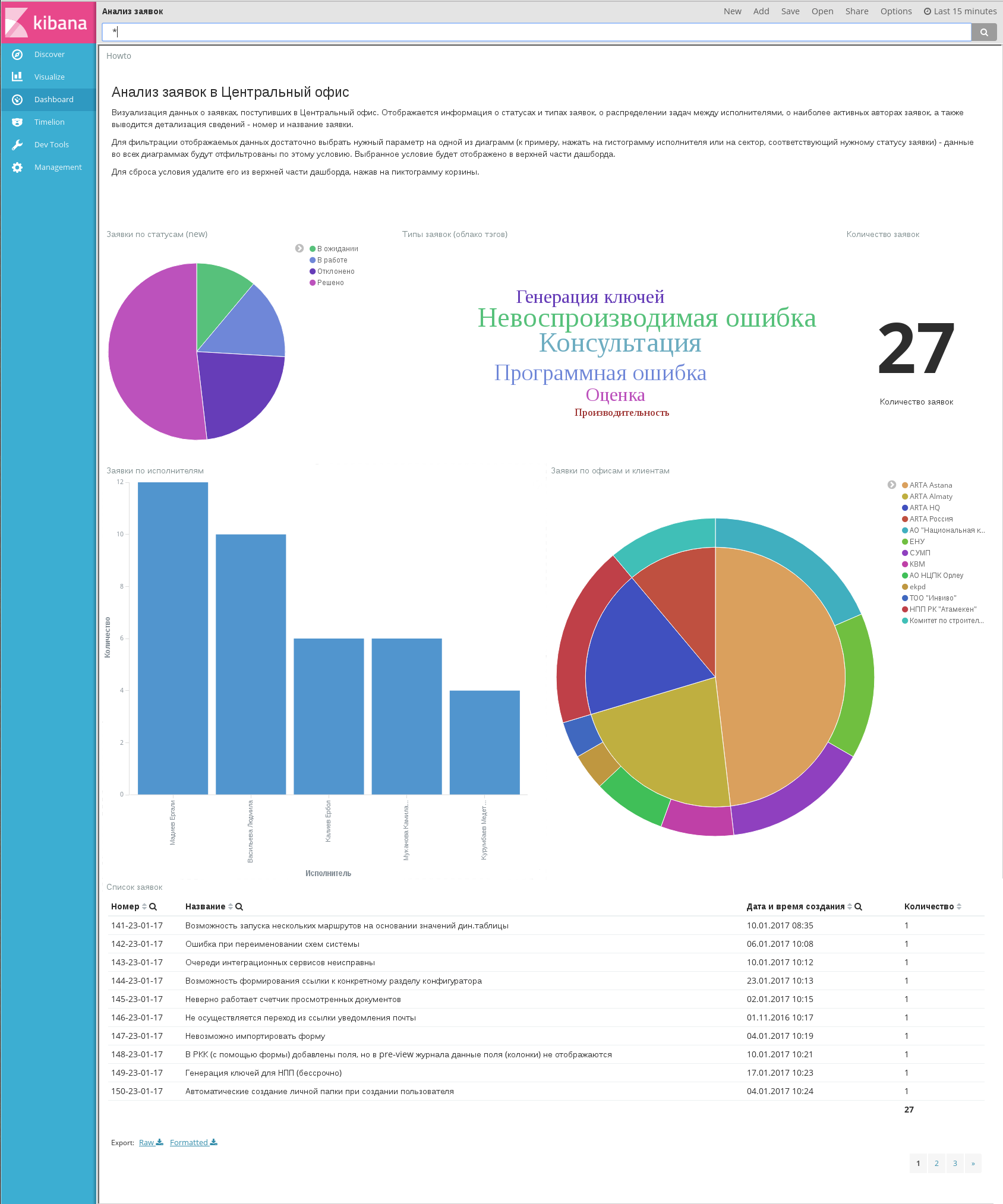
Пример готового дашборда в режиме редактирования
Типы использованных примеров диаграмм (перечислены сверху вниз, слева направо):
- Markdown widget
- Pie chart
- Tag cloud
- Metric
- Vertical bar chart
- Pie chart
- Data table
Предупреждение
Применение фильтров ко всем диаграммам на дашборде дает корректные результаты только в том случае, если коды используемых полей полностью совпадают (в том числе постфиксы). В случае, если необходимо отображение данных из нескольких форм, имеющих сквозные параметры (например, параметр «Статус»), необходимо, чтобы коды компоненов, соответствующих этому параметру, совпадали на всех формах, а в диаграммах использовалось одно и то же поле с учетом постфикса.
4.3.2.11. Публикация дашборда¶
Kibana предоставляет способы публикации дашборда как интерактивной диаграммы
или как снимка его состояния на момент публикации (shapshot). Публикация
производится в меню Share:
Пункт меню «Share»
Встраивание как дашборда, так и его снимка возможно двумя способами:
- как фрейма
html- код для вставки содержится в поле Embedded iframe; - как ссылки - URL страницы содержится в поле Link.
Подсказка
По URL, автоматически генерируемому Kibana, пользователям предоставляется дашборд в режиме редактирования, с правом доступа ко всем разделам Kibana. Для того, чтобы предоставить пользователям доступ к дашборду только в режиме просмотра, необходимо в URL ссылки добавить параметр:
&embed=true
Один из способов публикации дашборда в Synergy - добавление его как внешнего модуля. При этом каждый дашборд должен быть оформлен как отдельный внешний модуль. В качестве адреса приложения необходимо использовать URL дашборда.
Другой способ - включение фрейма с дашбордом в пользовательский компонент. В этом случае в качестве HTML-кода необходимо использовать код из поля Embedded iframe.
Подсказка
По умолчанию в код фрейма включены границы 800х600 пикселей. Для того, чтобы дашборд занимал все доступное место, необходимо изменить эти параметры:
height="100%" width="100%"
Параметр embed=true, означающий доступ к дашборду только в режиме просмотра,
включается Kibana по умолчанию.
Внимание
Обратите внимание, что для того, чтобы дашборд был доступен пользователю, у него должен быть доступ к серверу, на котором запущена Kibana.
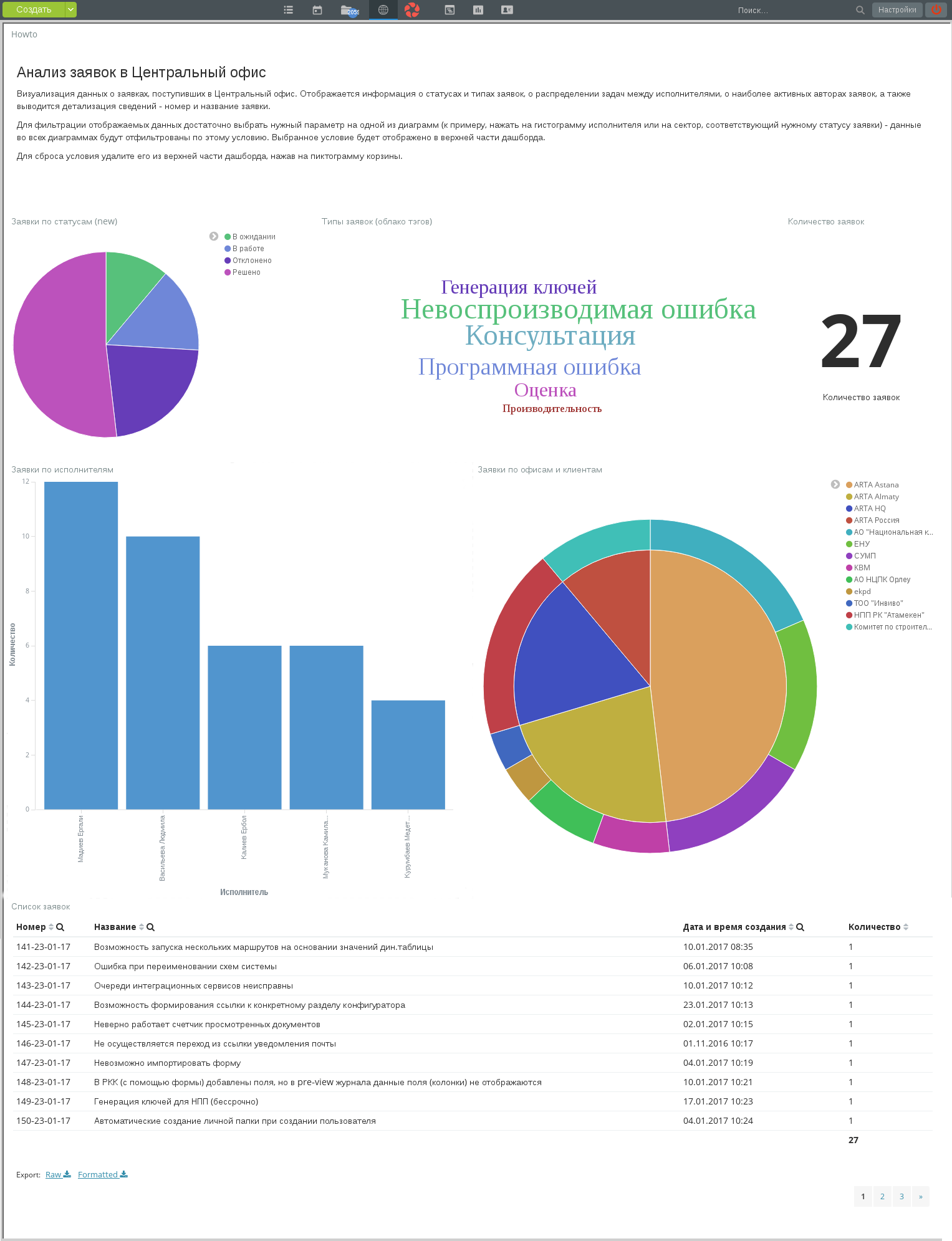
Пример дашборда, опубликованного как внешний модуль
4.4. Использование диаграмм¶
Все диаграммы Kibana, за исключением диаграмм Metric и Markdown widget, полностью интерактивны. Возможно «проваливание» по клику на любую часть диаграммы: при этом условие, соответствующее этой части, будет применено ко всем диаграммам на дашборде.
Рассмотрим использование диаграмм на примере ранее показанного дашборда «Анализ заявок в центральный офис» (илл. «Пример дашборда, опубликованного как внешний модуль»).
Подбор диаграмм на дашборде позволяет такие действия:
- просмотр всех заявок определенного статуса или типа;
- анализ загруженности и качества работы исполнителей;
- просмотр статуса заявок от выбранного центра решений или от выбранного клиента/проекта, и так далее.
В качестве примера детально рассмотрим действие «Просмотр всех заявок в статусе „Отклонено“».
Для просмотра сведений по отклоненным заявкам необходимо на диаграмме «Заявки по статусам» кликнуть на сектор, соответствующий статусу «Отклонено». Условие «Статус заявки» = «Отклонено» автоматически применится ко всем диаграммам (кроме Markdown widget):
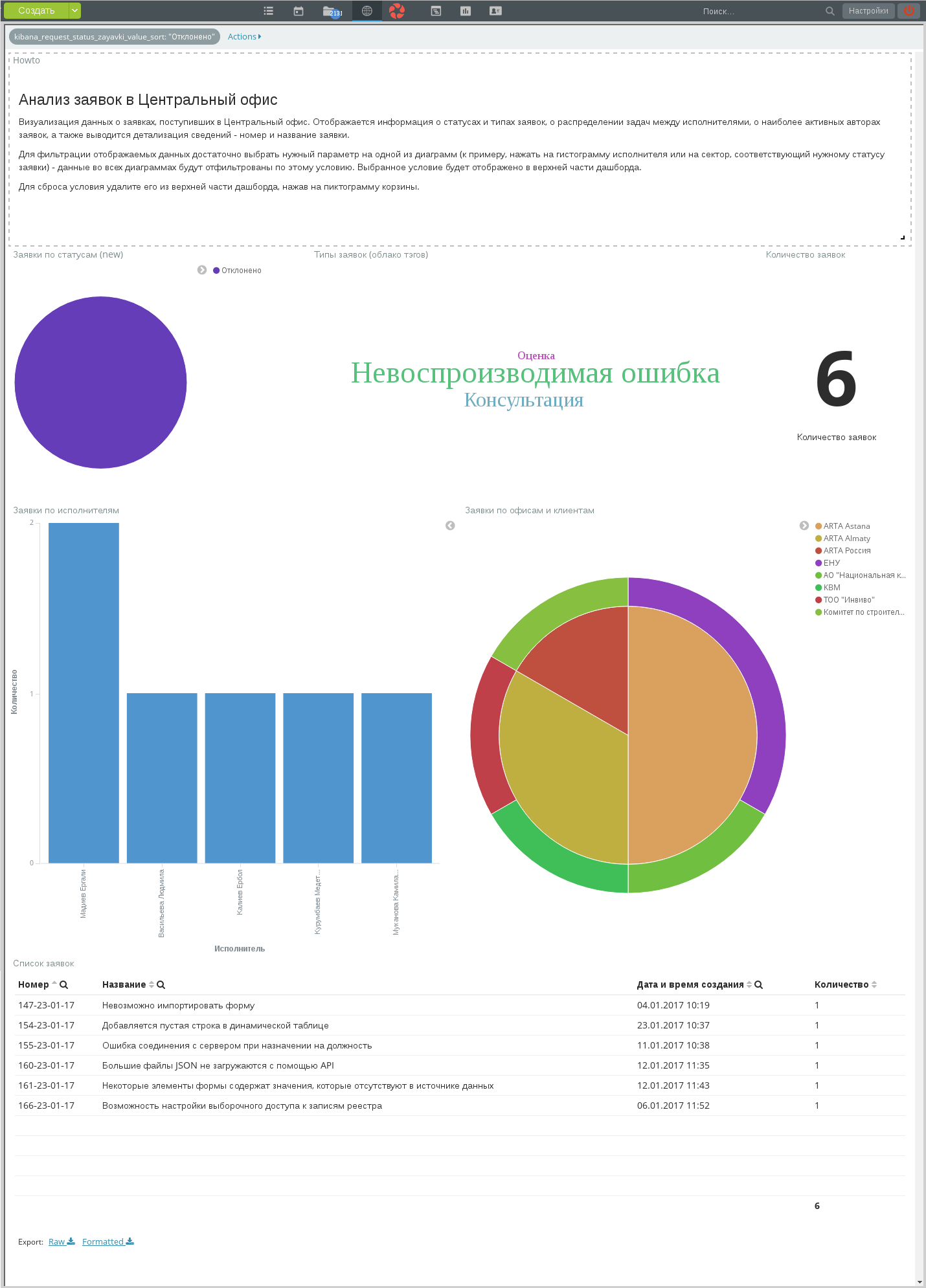
Условие на статус применено
Произошло «проваливание»: все диаграммы отображают результаты только по заявкам, имеющим статус «Отклонено». На примере видно, что всего было отклонено 6 заявок, больше всего из них имели тип «Невоспроизводимая ошибка». Также видно, какие центры решений подавали эти заявки, кто из исполнителей их отклонял. В нижней части дашборда таблица содержит перечень всех отклоненных заявок.
В верхней части дашборда отобразилась плашка примененного фильтра в формате
%название поля%: "%значение%". При наведении мыши на эту плашку отображаются
пиктограммы возможных действий с фильтром:
- включить/выключить фильтр;
- закрепить фильтр;
- отображать только результаты фильтрации / отображать все результаты;
- удалить фильтр;
- редактировать запрос для фильтра (синтаксис Elasticsearch).
Для того, чтобы применить еще одно условие (например, увидеть отклоненную заявку с типом «Оценка», достаточно в диаграмме Tag cloud кликнуть на лейбл с этим типом. Новое условие применится автоматически:
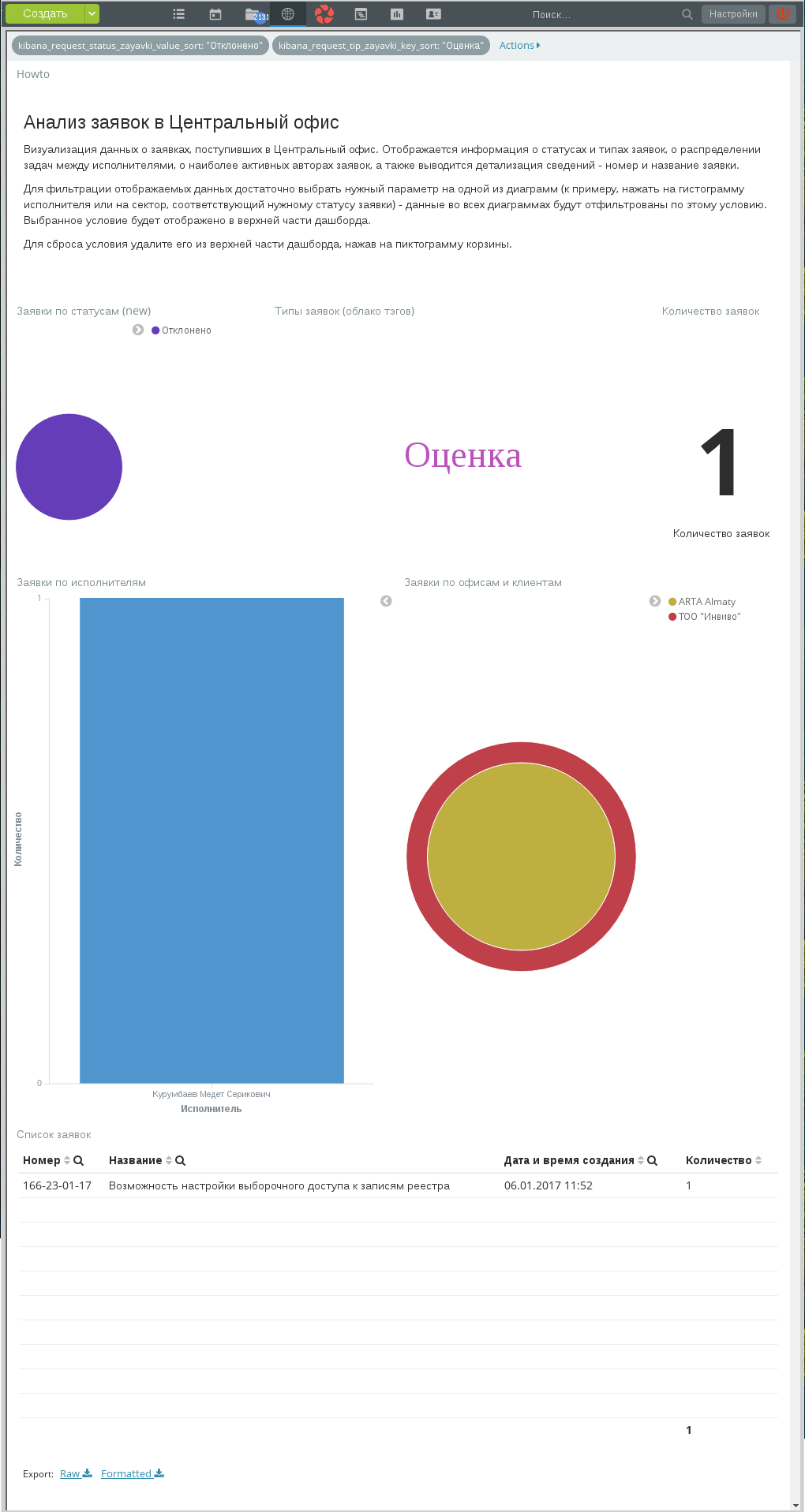
Условие на тип применено
Видно, что единственная отклоненная заявка с типом «Оценка» касалась возможности настройки выборочного доступа к записям реестра.
Новый фильтр отображен в верхней части дашборда. Кроме того, в верхней части доступно меню Actions, позволяющее действия одновременно над всеми фильтрами.
Предупреждение
Все фильтры применяются только для текущего пользователя и только на время текущего подключения. Каждый переход к внешнему модулю с диаграммами означает новое подключение к Kibana, и при этом все ранее сохраненные условия будут сброшены.
4.5. Возможные проблемы и способы их решения¶
4.5.1. Status: Red¶
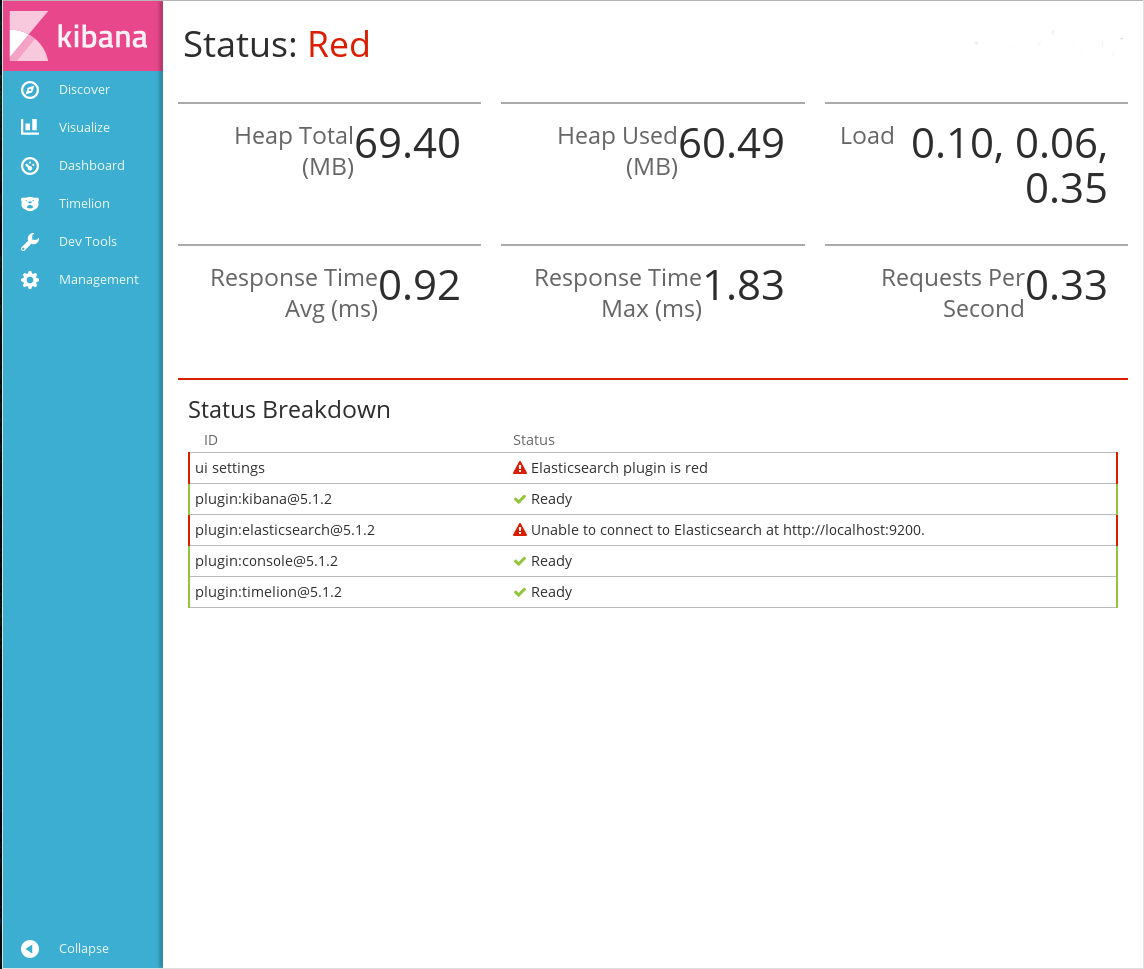
Ошибка связана с невозможностью доступа к сервису Easticsearch (ES). При ее возникновении сначала необходимо проверить статус ES. Для этого в консоли сервера, на котором запущен ES, выполните команду:
# /etc/init.d/elasticsearsh status
Результатом выполнения команды должно быть сообщение:
[ ok ] elasticsearch is running.
Другой способ - проверить статус ES непосредственно:
# curl localhost:9200
localhost:9200 - это адрес ES по умолчанию.
Вывод должен быть таким:
{
"name" : "RFSWkzt",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "r67YbmerQvyNHdxlzDIt3A",
"version" : {
"number" : "5.1.2",
"build_hash" : "c8c4c16",
"build_date" : "2017-01-11T20:18:39.146Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
Если при ошибке Status: Red результат выполнения этих команд совпадает с ожидаемым, это значит, что сервис Elasticsearch запустился, но еще не успел обработать все данных в индексах. Ошибка может возникать, если в ES загружен большой объем данных. В этом случае рекомендуется дать ES время на полную загрузку (до 30 минут).
Если спустя время статус Kibana не изменился, или в результате выполнения команды curl появляется сообщение о невозможности подсоединения к серверу, значит, необходимо перезапустить ES, выполнив команду:
# etc/init.d/elasticsearsh restart
4.5.2. Русскоязычные данные импортировались в ES как «????»¶
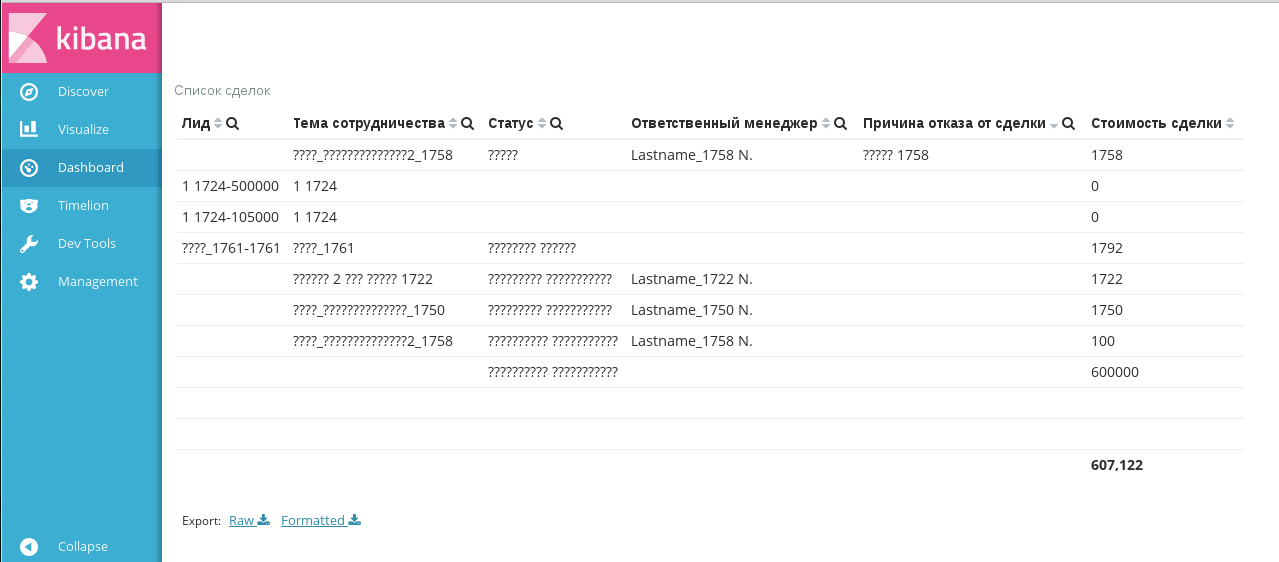
При возникновении такой проблемы рекомендуется:
Остановить запущенные сервисы, выполнив команды:
# /etc/init.d/arta-synergy-jboss stop # /etc/init.d/kibana stop # /etc/init.d/elasticsearch stop
Перейти к настройке локали сервера:
# dpkg-reconfigure localesВ качестве локали и локали по умолчанию установить локаль en_US.UTF-8.
Запустить Synergy и Elasticsearch:
# /etc/init.d/arta-synergy-jboss start # /etc/init.d/elasticsearch start
Выполнить полную переиндексацию данных форм в административном приложении Synergy.
Запустить Kibana:
# /etc/init.d/kibana start
4.5.3. Записи в реестре не отображаются в Synergy, но видны в результатах поиска по реестру и в данных Kibana¶
Остановить все сервисы:
# /etc/init.d/arta-synergy-jboss stop # /etc/init.d/kibana stop # /etc/init.d/elasticsearch stop
Удалить существующие индексы ES:
# rm -r /var/lib/elasticsearch/nodesЗапустить Synergy и Elasticsearch:
# /etc/init.d/arta-synergy-jboss start # /etc/init.d/elasticsearch start
Выполнить полную переиндексацию данных форм в административном приложении Synergy (Управление индексом форм).
Запустить Kibana:
# /etc/init.d/kibana start
4.5.4. При публикации дашбордов/диаграмм пользователи видят слева панель Kibana¶
Диаграмма/дашборд были опубликованы в режиме редактирования. Чтобы
избежать такой проблемы, необходимо в параметры URL-ссылки или HTML-фрейма
добавить параметр embed=true. Этот параметр означает, что данные должны
публиковаться в режиме просмотра.
4.5.5. При настроенной ссылке на дашборд/коду вставки HTML диаграммы не отображаются¶
Проблема возникает в том случае, если отключена Kibana. Необходимо проверить ее состояние:
в браузере перейти по адресу
<server.host>:<server.port>, где<server.host>- адрес сервера, на котором запущена Kibana, а<server.port>- номер порта (по умолчанию используется порт 5601)для проверки статуса из консоли сервера выполните команду:
# /etc/init.d/kibana statusРезультатом выполнения должно быть сообщение:
kibana is running
В случае, если Kibana не запущена или вернула ошибку, необходимо ее перезапустить, выполнив команду:
# /etc/init.d/kibana restart
4.5.6. Вместо диаграммы отображается сообщение «No results found»¶
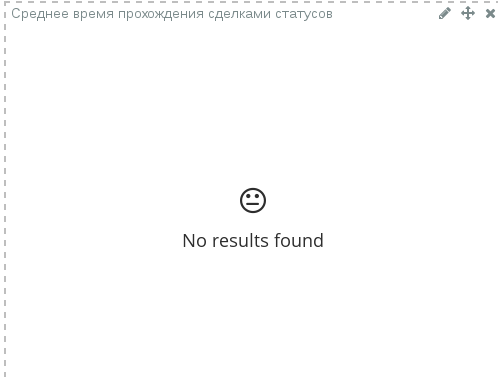
Kibana отображает в диаграммах только заполненные исходные данные. Диаграмма может не отображаться в двух случаях:
- К диаграмме было применено условие, результаты которого не используются в диаграмме.
- В исходных данных (в формах и реестрах Synergy) нет ни одного документа, данные из которого должны отобразиться в диаграмме.
Данное поведение не является ошибкой ни Kibana, ни Synergy, и при обновлении данных диаграммы отобразятся автоматически.
4.5.7. Диаграмма ссылается на недоступное поле¶
Проблема может возникнуть при импорте диаграмм из внешних источников
(в том числе при установке бизнес-приложений на базе Synergy, использующих
Kibana), и чаще всего связана с отсутствием в шаблоне индекса числового поля
с постфиксом _double. Проверить это можно, перейдя к настройке диаграммы:
в агрегациях по отсутствующим полям отображается ошибка.
Индекс для поля _double создается только в том случае, если из содержимого
поля удалось выделить число. То есть если во всех документах поле не заполнено,
то и индекс с типом double для него создан не будет.
Для того, чтобы исправить проблему, нужно хотя бы в одном документе по форме заполнить числовое поле, на отсутствие которого ссылается Kibana, после чего необходимо обновить шаблон индекса для диграммы, нажав на кнопку «Обновить» (раздел Management - Index patterns).
Для того, чтобы предотвратить возникновение такой ошибки, рекомендуется для каждого поля, которое будет использовано в диаграммах Kibana как числовое, сохранять значение по умолчанию в редакторе форм.
4.5.8. При обновлении данных в Synergy не обновляются соответствующие диаграммы¶
Проблема возникает из-за отсутствия или неправильной настройки периода обновления данных. Проверить эти настройки можно в Kibana:
Открыть дашборд, требующий настройки автообновления.
В панели меню выбрать настройки периода времени:
Выбрать пункт Auto-refresh:

Настроить Refresh Interval - периодичность обновления данных.
Осторожно
Не рекомендуется устанавливать периодичность обновления меньше, чем 30 секунд, поскольку на стороне пользователя может возникнуть проблема фризов (секундных подергиваний или застываний изображения).
4.5.9. После проведения индексации форм в Kibana отсутствуют данные форм¶
Возможно, не был переключен индексатор данных форм. По умолчанию в Synergy
для индексации данных используется система Lucene. Переключение индексаторов
между Lucene и ES осуществляется в файле
/opt/synergy/jboss/standalone/configuration/arta/esb/formIndex.xml.
Необходимо убедиться, что содержимое первого тэга <handler>, соответствующее
Lucene, закомментировано, и раскомментировать содержимое тэга после <elastic>
(относящееся к ES):
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<system xmlns="http://www.arta.kz/xml/ns/ai"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.arta.kz/xml/ns/ai http://www.arta.kz/xml/ns/ai/ai.xsd">
<name>synergy</name>
<clusterName>synergy</clusterName>
<host>127.0.0.1</host>
<port>9001</port>
<master>false</master>
<local>false</local>
<seed>false</seed>
<handlers>
<!--handler>
<name>indexForm</name>
<classname>kz.arta.synergy.indexator.forms.IndexFormHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>deleteForm</name>
<classname>kz.arta.synergy.indexator.forms.DeleteIndexFormHandler</classname>
<max-number>10</max-number>
</handler>
<handler>
<name>searchForms</name>
<classname>kz.arta.synergy.indexator.forms.SearchFormHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>searchRegistries</name>
<classname>kz.arta.synergy.indexator.forms.SearchRegistryHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>indexInfo</name>
<classname>kz.arta.synergy.indexator.forms.IndexInfoHandler</classname>
<max-number>1</max-number>
<properties>configuration.path=/opt/synergy/jboss/standalone/configuration/arta/formIndex.xml</properties>
</handler-->
<!--elastic-->
<handler>
<name>indexForm</name>
<classname>kz.arta.synergy.indexator.elastic.ElasticIndexFormHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>deleteForm</name>
<classname>kz.arta.synergy.indexator.elastic.ElasticDeleteIndexFormHandler</classname>
<max-number>10</max-number>
</handler>
<handler>
<name>searchForms</name>
<classname>kz.arta.synergy.indexator.elastic.ElasticSearchFormHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>searchRegistries</name>
<classname>kz.arta.synergy.indexator.elastic.ElasticSearchRegistryHandler</classname>
<max-number>30</max-number>
</handler>
<handler>
<name>indexInfo</name>
<classname>kz.arta.synergy.indexator.elastic.ElasticIndexInfoHandler</classname>
<max-number>1</max-number>
<properties>configuration.path=/opt/synergy/jboss/standalone/configuration/arta/elasticConfiguration.xml</properties>
</handler>
</handlers>
</system>
4.5.10. Не запускается Elasticsearch¶
Необходимо проверить, что ES действительно не запустился, поскольку возможна ситуация, что он еще не успел провести первичную обработку данных (см. пункт 1).
Проверка статуса ES может быть осуществлена двумя способами:
в консоли сервера, на котором запущен ES, выполните команду:
# /etc/init.d/elasticsearsh status
Результатом выполнения команды должно быть сообщение:
[ ok ] elasticsearch is running.
проверьте статус ES непосредственно:
# curl localhost:9200
localhost:9200- это адрес ES по умолчанию.Вывод должен быть таким:
{ "name" : "RFSWkzt", "cluster_name" : "elasticsearch", "cluster_uuid" : "r67YbmerQvyNHdxlzDIt3A", "version" : { "number" : "5.1.2", "build_hash" : "c8c4c16", "build_date" : "2017-01-11T20:18:39.146Z", "build_snapshot" : false, "lucene_version" : "6.3.0" }, "tagline" : "You Know, for Search" }
Если вывод отличается, проверьте указание переменной
JAVA_HOMEв файле/etc/default/elasticsearch:################################ # Elasticsearch ################################ # Elasticsearch home directory #ES_HOME=/usr/share/elasticsearch # Elasticsearch Java path JAVA_HOME=/usr/lib/jvm/java-8-oracle # Elasticsearch configuration directory #CONF_DIR=/etc/elasticsearch # Elasticsearch data directory #DATA_DIR=/var/lib/elasticsearch # Elasticsearch logs directory #LOG_DIR=/var/log/elasticsearch # Elasticsearch PID directory #PID_DIR=/var/run/elasticsearch # Additional Java OPTS #ES_JAVA_OPTS= # Configure restart on package upgrade (true, every other setting will lead to not restarting) #RESTART_ON_UPGRADE=true
Внимание
В качестве
JAVA_HOMEиспользуется полный путь к папкеbinиспользуемой версии Java. Строка с переменной должна быть раскомментирована.Перезапустите ES, выполнив команду:
# etc/init.d/elasticsearsh restart